
ENGR 1330 Computational Thinking with Data Science
Copyright © 2021 Theodore G. Cleveland and Farhang Forghanparast
Last GitHub Commit Date:
22: Testing Hypothesis - Comparing Collections¶
Comparing two (or more) collections
Parametric and Non-Parametric Tests
Type 1 & Type 2 errors
Background¶
In engineering, when we wish to start asking questions about the data and interpret the results, we use statistical methods that provide a confidence or likelihood about the answers. In general, this class of methods is called statistical hypothesis testing, or significance tests. The material for today’s lecture is inspired by and gathered from several resources including:
Hypothesis testing in Machine learning using Python by Yogesh Agrawal available at https://towardsdatascience.com/hypothesis-testing-in-machine-learning-using-python-a0dc89e169ce
Demystifying hypothesis testing with simple Python examples by Tirthajyoti Sarkar available at https://towardsdatascience.com/demystifying-hypothesis-testing-with-simple-python-examples-4997ad3c5294
A Gentle Introduction to Statistical Hypothesis Testing by Jason Brownlee available at https://machinelearningmastery.com/statistical-hypothesis-tests/
Let’s go over a few important concepts first.
What is hypothesis testing ?
¶
Hypothesis testing is a statistical method that is used in making statistical decisions (about population) using experimental data (samples). Hypothesis Testing is basically an assumption that we make about the population parameter.
Ex : you say on average, students in the class are taller than 5 ft and 4 inches or an average boy is taller than girls or a specific treatment is effective in treating COVID-19 patients.
We need some mathematical conclusion that whatever we are assuming is true. We will validate our hypotheses, basing our conclusion on random samples and empirical distributions._
Why do we use it ?
¶
Hypothesis testing is an essential procedure in statistics. A hypothesis test evaluates two mutually exclusive statements about a population to determine which statement is best supported by the sample data. When we say that a finding is statistically significant, it’s thanks to a hypothesis test._
Which are important elements of hypothesis testing ?
¶
Null hypothesis:
The assertion of a statistical test is called the null hypothesis, or hypothesis 0 (H0 for short). It is often called the default assumption, or the assumption that nothing has changed. In inferential statistics, the null hypothesis is a general statement or default position that there is no relationship between two measured phenomena, or no association among groups. In other words it is a basic assertion made based on domain or problem knowledge.
Example : a company’s gadget production is = 50 unit/per day.
Alternative hypothesis:
A violation of the test’s assertion is often called the first hypothesis, hypothesis 1 or H1 for short. H1 is really a short hand for “some other hypothesis,” as all we know is that the evidence suggests that the H0 can be rejected. The alternative hypothesis is the hypothesis used in hypothesis testing that is contrary to the null hypothesis. It is usually taken to be that the observations are the result of a real effect (with some amount of chance variation superposed). Example : a company’s production is !=50 unit/per day.
What are basic of hypothesis ?
¶
A fundamental stipulation is normalisation and standard normalisation. all our assertions and alternatives revolve around these 2 terms.
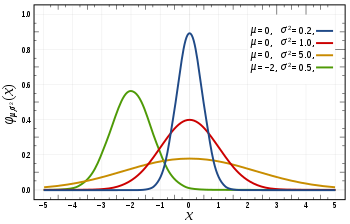
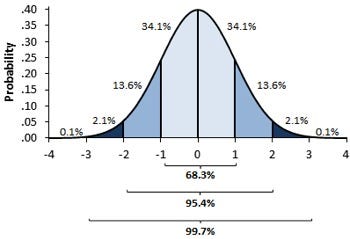
in the 1st image, you can see there are different normal curves. Those normal curves have different means and variances. In the 2nd image if you notice the graph is properly distributed with a mean =0 and variance =1. Concept of z-score comes in picture when we use standardized normal data.
Normal Distribution:¶
A variable is said to be normally distributed or have a normal distribution if its distribution has the shape of a normal curve — a special bell-shaped curve. The graph of a normal distribution is called the normal curve, for which the mean, median, and mode are equal. (The 1st Image)
Standardised Normal Distribution:¶
A standard normal distribution is a normal distribution with mean 0 and standard deviation 1 (The 2nd Image)
Z score:
¶
It is a method of expressing data in relation to the group mean. To obtain the Z-score of a particular data, we calculate its deviation from the mean and then divide it by the SD.

The Z score is one way of standardizing a score so that it can be referred to a standard normal distribution curve.

Read more on Z-Score @
Z-Score: Definition, Formula and Calculation available at https://www.statisticshowto.com/probability-and-statistics/z-score/
Z-Score: Definition, Calculation and Interpretation by Saul McLeod available at https://www.simplypsychology.org/z-score.html
Tailing of Hypothesis:
¶
Depending on the research question hypothesis can be of 2 types. In the Nondirectional (two-tailed) test the Research Question is like: Is there a (statistically) significant difference between scores of Group-A and Group-B in a certain competition? In Directional (one-tailed) test the Research Question is like: Do Group-A score significantly higher than Group-B in a certain competition?

Read more on Tailing @
One- and two-tailed tests available at https://en.wikipedia.org/wiki/One-_and_two-tailed_tests
Z-Score: Definition, Calculation and Interpretation by Saul McLeod available at https://www.simplypsychology.org/z-score.html
Level of significance:
¶

Refers to the degree of significance in which we accept or reject the null-hypothesis. 100% accuracy is not possible for accepting or rejecting a hypothesis, so we therefore select a level of significance.
This significance level is usually denoted with alpha \(\alpha\) and often it is set to 0.05 or 5% , which means your output should be 95% confident to give similar kind of result in each sample. A smaller alpha value suggests a more robust interpretation of the null hypothesis, such as 1% or 0.1%.
P-value :
¶
The P value, or attained (calculated) probability, is the probability (p-value) of the collected data, given that the null hypothesis was true. The p-value reflects the strength of evidence against the null hypothesis. Accordingly, we’ll encounter two situations: the strength is strong enough or not strong enough to reject the null hypothesis.
The p-value is compared to the pre-chosen alpha value. A result is statistically significant when the p-value is less than alpha. If your P value is less than the chosen significance level then you reject the null hypothesis i.e. accept that your sample gives reasonable evidence to support the alternative hypothesis.
Note
If p-value > alpha: Do not reject the null hypothesis (i.e. not significant result).
If p-value <= alpha: Reject the null hypothesis (i.e. significant result).

For example, if we were performing a test of whether a data sample was normally distributed and we calculated a p-value of .07, we could state something like:
"The test found that the data sample was normal, failing to reject the null hypothesis at a 5% significance level.""
The significance level can be inverted by subtracting it from 1 to give a confidence level of the hypothesis given the observed sample data. Therefore, statements such as the following can also be made:
"The test found that the data was normal, failing to reject the null hypothesis at a 95% confidence level.""
Example :
¶
You have a coin and you don’t know whether that is fair or tricky so let’s decide null and alternate hypothes is
H0 : a coin is a fair coin.
H1 : a coin is a tricky coin.
alpha = 5% or 0.05
Now let’s toss the coin and calculate p-value (probability value).
Toss a coin 1st time (sample size =1) and result is tail
P-value = 50% (as head and tail have equal probability)
Toss a coin 2nd time (sample size =2) and result is tail, now
P-value = 50/2 = 25%
and similarly suppose we Toss 6 consecutive times (sample size =6) and got result as P-value = 1.5%
print("probability of 6 tails in 6 tosses if coin is fair",round((0.5)**6,3))
probability of 6 tails in 6 tosses if coin is fair 0.016
but we set our significance level as 5%. Here we see we are beyond that level i.e. our null- hypothesis does not hold good so we need to reject and propose that this coin is not fair. It does not necessarily mean that the coin is tricky, but 6 tails in a row is quite unlikely with a fair coin, and a good “bet” would be to reject the coin as unfair, and 95% of the time you would be correct.
Alternatively, one could phrase the result as a fair coin would produce a result other than 6 tails in a row 98.5% of the time.
Read more on p-value @
P-values Explained By Data Scientist For Data Scientists by Admond Lee available at https://towardsdatascience.com/p-values-explained-by-data-scientist-f40a746cfc8
What a p-Value Tells You about Statistical Data by Deborah J. Rumsey available at https://www.dummies.com/education/math/statistics/what-a-p-value-tells-you-about-statistical-data/
Key to statistical result interpretation: P-value in plain English by Tran Quang Hung available at https://s4be.cochrane.org/blog/2016/03/21/p-value-in-plain-english-2/
Watch more on p-value @
StatQuest: P Values, clearly explained available at https://www.youtube.com/watch?v=5Z9OIYA8He8
Understanding the p-value - Statistics Help available at https://www.youtube.com/watch?v=eyknGvncKLw
What Is A P-Value? - Clearly Explained available at https://www.youtube.com/watch?v=ukcFrzt6cHk
“Reject” vs “Failure to Reject”
¶
The p-value is probabilistic. This means that when we interpret the result of a statistical test, we do not know what is true or false, only what is likely. Rejecting the null hypothesis means that there is sufficient statistical evidence (from the samples) that the null hypothesis does not look likely (for the population). Otherwise, it means that there is not sufficient statistical evidence to reject the null hypothesis.
We may think about the statistical test in terms of the dichotomy of rejecting and accepting the null hypothesis. The danger is that if we say that we “accept” the null hypothesis, the “language” implies that the null hypothesis is true. Instead, it is more preferred to say that we “fail to reject” the null hypothesis, as in, there is insufficient statistical evidence to reject it.
Errors in Statistical Tests
¶
The interpretation of a statistical hypothesis test is probabilistic. That means that the evidence of the test may suggest an outcome and be mistaken. For example, if alpha was 5%, it suggests that (at most) 1 time in 20 that the null hypothesis would be mistakenly rejected or failed to be rejected (e.g., because of the statistical noise in the data sample).
Having a small p-value (rejecting the null hypothesis) either means that the null hypothesis is false (we got it right) or it is true and some rare and unlikely event has been observed (we made a mistake). If this type of error is made, it is called a false positive. We falsely rejected of the null hypothesis.
Alternately, given a large p-value (failing to reject the null hypothesis), it may mean that the null hypothesis is true (we got it right) or that the null hypothesis is false and some unlikely event occurred (we made a mistake). If this type of error is made, it is called a false negative. We falsely believe the null hypothesis or assumption of the statistical test.
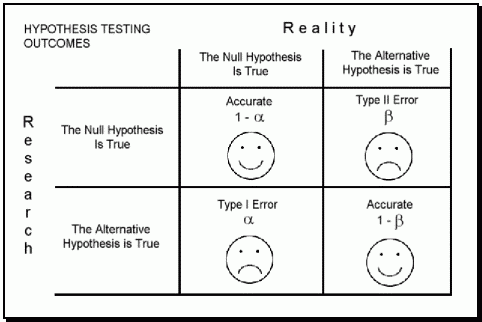
Each of these two types of error has a specific name:
Type I Error: The incorrect rejection of a true null hypothesis or a false positive.
Type II Error: The incorrect failure of rejection of a false null hypothesis or a false negative.

All statistical hypothesis tests have a risk of making either of these types of errors. False findings are more than just possible; they are probable!
Ideally, we want to choose a significance level that minimizes the likelihood of one of these errors. E.g. a very small significance level. Although significance levels such as 0.05 and 0.01 are common in many fields of science, harder sciences (as defined by Dr. Sheldon Cooper), such as physics, are more aggressive.
Read more on Type I and Type II Errors @
Type I and type II errors available at https://en.wikipedia.org/wiki/Type_I_and_type_II_errors#:~:text=In statistical hypothesis testing, a,false negative” finding or conclusion
To Err is Human: What are Type I and II Errors? available at https://www.statisticssolutions.com/to-err-is-human-what-are-type-i-and-ii-errors/
Statistics: What are Type 1 and Type 2 Errors? available at https://www.abtasty.com/blog/type-1-and-type-2-errors/
Some Important Statistical Hypothesis Tests
¶
Variable Distribution Type Tests (Gaussian)
Shapiro-Wilk Test
D’Agostino’s K^2 Test
Anderson-Darling Test
Compare Sample Means (parametric)
Student’s t-test
Paired Student’s t-test
Analysis of Variance Test (ANOVA)
Repeated Measures ANOVA Test
Compare Sample Means (nonparametric)
Mann-Whitney U Test
Wilcoxon Signed-Rank Test
Kruskal-Wallis H Test
Friedman Test
Check these excellent links to read more on different Statistical Hypothesis Tests:_
17 Statistical Hypothesis Tests in Python (Cheat Sheet) by *Jason Brownlee * available at https://machinelearningmastery.com/statistical-hypothesis-tests-in-python-cheat-sheet/
Statistical Tests — When to use Which ? by vibhor nigam available at https://towardsdatascience.com/statistical-tests-when-to-use-which-704557554740
Comparing Hypothesis Tests for Continuous, Binary, and Count Data by Jim Frost available at https://statisticsbyjim.com/hypothesis-testing/comparing-hypothesis-tests-data-types/
Normality Tests: Shapiro-Wilk Test
¶
Tests whether a data sample has a Gaussian distribution.
Assumptions:
Observations in each sample are independent and identically distributed (iid).
Interpretation:
H0: the sample has a Gaussian distribution.
H1: the sample does not have a Gaussian distribution.
# Example of the Shapiro-Wilk Normality Test
from scipy.stats import shapiro
data = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
stat, p = shapiro(data)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably Gaussian')
else:
print('Probably not Gaussian')
stat=0.895, p=0.193
Probably Gaussian
Normality Tests: D’Agostino’s K^2 Test
¶
Tests whether a data sample has a Gaussian distribution.
Assumptions:
Observations in each sample are independent and identically distributed (iid).
Interpretation:
H0: the sample has a Gaussian distribution.
H1: the sample does not have a Gaussian distribution.
# Example of the D'Agostino's K^2 Normality Test
from scipy.stats import normaltest
data = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
stat, p = normaltest(data)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably Gaussian')
else:
print('Probably not Gaussian')
stat=3.392, p=0.183
Probably Gaussian
/opt/jupyterhub/lib/python3.8/site-packages/scipy/stats/stats.py:1603: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=10
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
Read more on Normality Tests @
A Gentle Introduction to Normality Tests in Python by Jason Brownlee available at https://machinelearningmastery.com/a-gentle-introduction-to-normality-tests-in-python/
Parametric Statistical Hypothesis Tests: Student’s t-test
¶
Tests whether the means of two independent samples are significantly different.
Assumptions:
Observations in each sample are independent and identically distributed (iid).
Observations in each sample are normally distributed.
Observations in each sample have the same variance.
Interpretation:
H0: the means of the samples are equal.
H1: the means of the samples are unequal.
# Example of the Student's t-test
from scipy.stats import ttest_ind
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = ttest_ind(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
stat=-0.326, p=0.748
Probably the same distribution
Parametric Statistical Hypothesis Tests: Paired Student’s t-test
¶
Tests whether the means of two paired samples are significantly different.
Assumptions:
Observations in each sample are independent and identically distributed (iid).
Observations in each sample are normally distributed.
Observations in each sample have the same variance.
Observations across each sample are paired.
Interpretation:
H0: the means of the samples are equal.
H1: the means of the samples are unequal.
# Example of the Paired Student's t-test
from scipy.stats import ttest_rel
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = ttest_rel(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
stat=-0.334, p=0.746
Probably the same distribution
Parametric Statistical Hypothesis Tests: Analysis of Variance Test (ANOVA)
¶
Tests whether the means of two or more independent samples are significantly different.
Assumptions:
Observations in each sample are independent and identically distributed (iid).
Observations in each sample are normally distributed.
Observations in each sample have the same variance.
Interpretation:
H0: the means of the samples are equal.
H1: one or more of the means of the samples are unequal.
# Example of the Analysis of Variance Test
from scipy.stats import f_oneway
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
data3 = [-0.208, 0.696, 0.928, -1.148, -0.213, 0.229, 0.137, 0.269, -0.870, -1.204]
stat, p = f_oneway(data1, data2, data3)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
stat=0.096, p=0.908
Probably the same distribution
Read more on Parametric Statistical Hypothesis Tests @
How to Calculate Parametric Statistical Hypothesis Tests in Python by Jason Brownlee available at https://machinelearningmastery.com/parametric-statistical-significance-tests-in-python/
Nonparametric Statistical Hypothesis Tests: Mann-Whitney U Test
¶
Tests whether the distributions of two independent samples are equal or not.
Assumptions:
Observations in each sample are independent and identically distributed (iid).
Observations in each sample can be ranked.
Interpretation:
H0: the distributions of both samples are equal.
H1: the distributions of both samples are not equal.
# Example of the Mann-Whitney U Test
from scipy.stats import mannwhitneyu
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = mannwhitneyu(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
stat=40.000, p=0.236
Probably the same distribution
Nonparametric Statistical Hypothesis Tests: Wilcoxon Signed-Rank Test
¶
Tests whether the distributions of two paired samples are equal or not.
Assumptions:
Observations in each sample are independent and identically distributed (iid).:
Observations in each sample can be ranked.
Observations across each sample are paired.
Interpretation:
H0: the distributions of both samples are equal.
H1: the distributions of both samples are not equal.
# Example of the Wilcoxon Signed-Rank Test
from scipy.stats import wilcoxon
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = wilcoxon(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
stat=21.000, p=0.557
Probably the same distribution
Nonparametric Statistical Hypothesis Tests: Kruskal-Wallis H Test
¶
Tests whether the distributions of two or more independent samples are equal or not.
Assumptions:
Observations in each sample are independent and identically distributed (iid).
Observations in each sample can be ranked.
Interpretation:
H0: the distributions of all samples are equal.
H1: the distributions of one or more samples are not equal.
# Example of the Kruskal-Wallis H Test
from scipy.stats import kruskal
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = kruskal(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
stat=0.571, p=0.450
Probably the same distribution
Read more on Nonparametric Statistical Hypothesis Tests @
How to Calculate Nonparametric Statistical Hypothesis Tests in Python by Jason Brownlee available at https://machinelearningmastery.com/nonparametric-statistical-significance-tests-in-python/
Background¶
The Clean Water Act (CWA) prohibits storm water discharge from construction sites
that disturb 5 or more acres, unless authorized by a National Pollutant Discharge
Elimination System (NPDES) permit. Permittees must provide a site description,
identify sources of contaminants that will affect storm water, identify appropriate
measures to reduce pollutants in stormwater discharges, and implement these measures.
The appropriate measures are further divided into four classes: erosion and
sediment control, stabilization practices, structural practices, and storm water management.
Collectively the site description and accompanying measures are known as
the facility’s Storm Water Pollution Prevention Plan (SW3P).
The permit contains no specific performance measures for construction activities,
but states that ”EPA anticipates that storm water management will be able to
provide for the removal of at least 80% of the total suspended solids (TSS).” The
rules also note ”TSS can be used as an indicator parameter to characterize the
control of other pollutants, including heavy metals, oxygen demanding pollutants,
and nutrients commonly found in stormwater discharges”; therefore, solids control is
critical to the success of any SW3P.
Although the NPDES permit requires SW3Ps to be in-place, it does not require
any performance measures as to the effectiveness of the controls with respect to
construction activities. The reason for the exclusion was to reduce costs associated
with monitoring storm water discharges, but unfortunately the exclusion also makes
it difficult for a permittee to assess the effectiveness of the controls implemented at
their site. Assessing the effectiveness of controls will aid the permittee concerned
with selecting the most cost effective SW3P.
Problem Statement
¶
The files precon.CSV and durcon.CSV contain observations of cumulative
rainfall, total solids, and total suspended solids collected from a construction
site on Nasa Road 1 in Harris County.
The data in the file precon.CSV was collected before construction began. The data in the file durcon.CSV were collected during the construction activity.
The first column is the date that the observation was made, the second column the total solids (by standard methods), the third column is is the total suspended solids (also by standard methods), and the last column is the cumulative rainfall for that storm.
Note
Script to get the files automatically is listed below this note:
import requests # Module to process http/https requests
remote_url="http://54.243.252.9/engr-1330-webroot/9-MyJupyterNotebooks/41A-HypothesisTests/precon.csv" # set the url
rget = requests.get(remote_url, allow_redirects=True) # get the remote resource, follow imbedded links
open('precon.csv','wb').write(rget.content) # extract from the remote the contents, assign to a local file same name
remote_url="http://54.243.252.9/engr-1330-webroot/9-MyJupyterNotebooks/41A-HypothesisTests/durcon.csv" # set the url
rget = requests.get(remote_url, allow_redirects=True) # get the remote resource, follow imbedded links
open('durcon.csv','wb').write(rget.content) # extract from the remote the contents, assign to a local file same name
These data are not time series (there was sufficient time between site visits that you can safely assume each storm was independent. Our task is to analyze these two data sets and decide if construction activities impact stormwater quality in terms of solids measures.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Read and examine the files, see if we can understand their structure
precon = pd.read_csv("precon.csv")
durcon = pd.read_csv("durcon.csv")
precon
| DATE | TS.PRE | TSS.PRE | RAIN.PRE | |
|---|---|---|---|---|
| 0 | 03/27/97 | 408.5 | 111.0 | 1.00 |
| 1 | 03/31/97 | 524.5 | 205.5 | 0.52 |
| 2 | 04/04/97 | 171.5 | 249.0 | 0.95 |
| 3 | 04/07/97 | 436.5 | 65.0 | 0.55 |
| 4 | 04/11/97 | 627.0 | 510.5 | 2.19 |
| 5 | 04/18/97 | 412.5 | 93.0 | 0.20 |
| 6 | 04/26/97 | 434.0 | 224.0 | 3.76 |
| 7 | 04/27/97 | 389.5 | 187.0 | 0.13 |
| 8 | 05/10/97 | 247.0 | 141.5 | 0.70 |
| 9 | 05/14/97 | 163.0 | 87.0 | 0.19 |
| 10 | 05/16/97 | 283.5 | 160.5 | 0.94 |
| 11 | 05/23/97 | 193.0 | 25.0 | 0.71 |
| 12 | 05/27/97 | 268.0 | 364.5 | 0.46 |
| 13 | 05/29/97 | 359.5 | 276.0 | 0.99 |
| 14 | 06/02/97 | 1742.0 | 1373.0 | 0.65 |
| 15 | 06/09/97 | 595.0 | 492.5 | 0.30 |
| 16 | 06/18/97 | 615.0 | 312.0 | 0.69 |
durcon
| TS.DUR | TSS.DUR | RAIN.DUR | |
|---|---|---|---|
| 0 | 3014.0 | 2871.5 | 1.59 |
| 1 | 1137.0 | 602.0 | 0.53 |
| 2 | 2362.5 | 2515.0 | 0.74 |
| 3 | 395.5 | 130.0 | 0.11 |
| 4 | 278.5 | 36.5 | 0.27 |
| 5 | 506.5 | 320.5 | 0.69 |
| 6 | 2829.5 | 3071.5 | 1.06 |
| 7 | 22209.5 | 17424.5 | 6.55 |
| 8 | 2491.5 | 1931.5 | 0.83 |
| 9 | 1278.0 | 1129.5 | 0.91 |
| 10 | 1428.5 | 1328.0 | 1.06 |
| 11 | 274.5 | 193.5 | 0.31 |
| 12 | 435.0 | 243.0 | 0.15 |
| 13 | 213.0 | 57.0 | 1.04 |
| 14 | 329.0 | 71.0 | 0.51 |
| 15 | 228.0 | 25.0 | 1.01 |
| 16 | 270.0 | 22.0 | 0.10 |
| 17 | 260.0 | 44.0 | 0.13 |
| 18 | 3176.5 | 2401.0 | 0.28 |
| 19 | 29954.5 | 24146.5 | 3.55 |
| 20 | 26099.5 | 15454.0 | 4.91 |
| 21 | 1484.0 | 1268.0 | 3.33 |
| 22 | 146.0 | 43.0 | 1.00 |
| 23 | 1069.0 | 891.0 | 0.51 |
| 24 | 242.0 | 38.0 | 0.14 |
| 25 | 5310.0 | 6103.0 | 0.50 |
| 26 | 2671.5 | 2737.0 | 0.75 |
| 27 | 214.0 | 29.0 | 0.10 |
| 28 | 1058.0 | 776.5 | 0.80 |
| 29 | 319.5 | 263.0 | 0.48 |
| 30 | 4864.0 | 4865.0 | 0.68 |
| 31 | 2647.0 | 2473.0 | 0.10 |
| 32 | 259.0 | 14.0 | 0.10 |
| 33 | 124.0 | 45.0 | 0.28 |
| 34 | 9014.5 | 7680.5 | 1.77 |
| 35 | 159.0 | 80.0 | 0.19 |
| 36 | 573.0 | 397.5 | 0.55 |
precon.describe()
| TS.PRE | TSS.PRE | RAIN.PRE | |
|---|---|---|---|
| count | 17.000000 | 17.000000 | 17.000000 |
| mean | 462.941176 | 286.882353 | 0.878235 |
| std | 361.852779 | 312.659786 | 0.882045 |
| min | 163.000000 | 25.000000 | 0.130000 |
| 25% | 268.000000 | 111.000000 | 0.460000 |
| 50% | 408.500000 | 205.500000 | 0.690000 |
| 75% | 524.500000 | 312.000000 | 0.950000 |
| max | 1742.000000 | 1373.000000 | 3.760000 |
durcon.describe()
| TS.DUR | TSS.DUR | RAIN.DUR | |
|---|---|---|---|
| count | 37.000000 | 37.000000 | 37.000000 |
| mean | 3495.283784 | 2749.216216 | 1.016486 |
| std | 7104.602041 | 5322.194188 | 1.391886 |
| min | 124.000000 | 14.000000 | 0.100000 |
| 25% | 270.000000 | 57.000000 | 0.270000 |
| 50% | 1058.000000 | 602.000000 | 0.550000 |
| 75% | 2671.500000 | 2515.000000 | 1.010000 |
| max | 29954.500000 | 24146.500000 | 6.550000 |
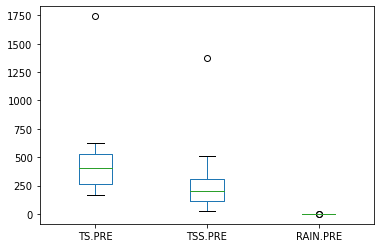
precon.plot.box()
<AxesSubplot:>
durcon.plot.box()
<AxesSubplot:>
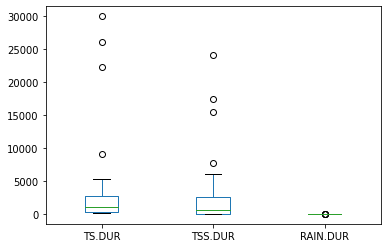
Here we see that the scales of the two data sets are quite different. Let’s see if the two construction phases represent approximately the same rainfall conditions?
precon['RAIN.PRE'].describe()
count 17.000000
mean 0.878235
std 0.882045
min 0.130000
25% 0.460000
50% 0.690000
75% 0.950000
max 3.760000
Name: RAIN.PRE, dtype: float64
durcon['RAIN.DUR'].describe()
count 37.000000
mean 1.016486
std 1.391886
min 0.100000
25% 0.270000
50% 0.550000
75% 1.010000
max 6.550000
Name: RAIN.DUR, dtype: float64
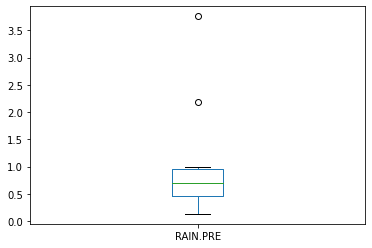
If we look at the summary statistics, we might conclude there is more rainfall during construction, which could bias our interpretation, a box plot of just rainfall might be useful, as would hypothesis tests.
precon['RAIN.PRE'].plot.box()
<AxesSubplot:>
durcon['RAIN.DUR'].plot.box()
<AxesSubplot:>
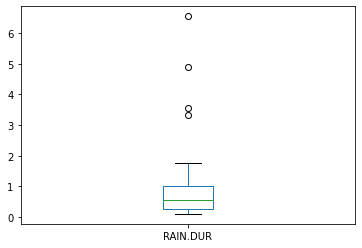
Hard to tell from the plots, they look a little different, but are they? Lets apply some hypothesis tests
from scipy.stats import mannwhitneyu # import a useful non-parametric test
stat, p = mannwhitneyu(precon['RAIN.PRE'],durcon['RAIN.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
statistic=291.500, p-value at rejection =0.338
Probably the same distribution
from scipy import stats
results = stats.ttest_ind(precon['RAIN.PRE'], durcon['RAIN.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f ' % (results[0], results[1]))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
statistic=-0.375, p-value at rejection =0.709
Probably the same distribution
From these two tests (the data are NOT paired) we conclude that the two sets of data originate from the same distribution. Thus the question “Do the two construction phases represent approximately the same rainfall conditions?” can be safely answered in the affirmative.
Continuing, lets ask the same about total solids, first plots:
precon['TS.PRE'].plot.box()
<AxesSubplot:>
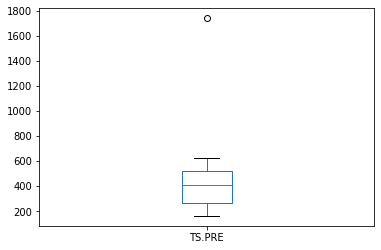
durcon['TS.DUR'].plot.box()
<AxesSubplot:>
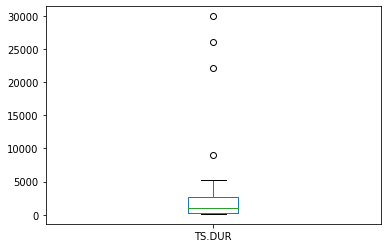
Look at the difference in scales, the during construction phase, is about 5 to 10 times greater. But lets apply some tests to formalize our interpretation.
stat, p = mannwhitneyu(precon['TS.PRE'],durcon['TS.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
statistic=221.000, p-value at rejection =0.042
Probably different distributions
results = stats.ttest_ind(precon['TS.PRE'], durcon['TS.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f ' % (results[0], results[1]))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
statistic=-1.750, p-value at rejection =0.086
Probably different distributions
Both these tests indicate that the data derive from distirbutions with different measures of central tendency (means). Lets now ask the question about normality, we will apply a test called normaltest. This function tests a null hypothesis that a sample comes from a normal distribution. It is based on D’Agostino and Pearson’s test that combines skew and kurtosis to produce an omnibus test of normality. We will likely get a warning because our sample size is pretty small.
stat, p = stats.normaltest(precon['TS.PRE'])
print('statistic=%.3f, p-value at rejection =%.3f' % (stat, p))
if p > 0.05:
print('Probably normal distributed')
else:
print('Probably Not-normal distributed')
statistic=32.081, p-value at rejection =0.000
Probably Not-normal distributed
/opt/jupyterhub/lib/python3.8/site-packages/scipy/stats/stats.py:1603: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=17
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
stat, p = stats.normaltest(durcon['TS.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f' % (stat, p))
if p > 0.05:
print('Probably normal distributed')
else:
print('Probably Not-normal distributed')
statistic=41.701, p-value at rejection =0.000
Probably Not-normal distributed
References¶
D’Agostino, R. B. (1971), “An omnibus test of normality for moderate and large sample size”, Biometrika, 58, 341-348
D’Agostino, R. and Pearson, E. S. (1973), “Tests for departure from normality”, Biometrika, 60, 613-622
References¶
Laboratory 22¶
Examine (click) Laboratory 22 as a webpage at Laboratory 22.html
Download (right-click, save target as …) Laboratory 22 as a jupyterlab notebook from Laboratory 22.ipynb
Exercise Set 22¶
Examine (click) Exercise Set 22 as a webpage at Exercise 22.html
Download (right-click, save target as …) Exercise Set 21 as a jupyterlab notebook at Exercise Set 22.ipynb