14.4 Artifical Neural Network to Detect Cracks#
In this example we will apply our single-layer ANN model to detect cracks in images. Here we are flattening the images so will lose spatial information, might consider a convolution kernel to preserve spatial relationships.
The data are sourced from:
Workflow:
Destroy existing data (need explained below)
Obtain the original dataset (.zip)
Use python libraries to extract the images; they are stored in MatLab.mat file structures.
Store imgaes locally into subdirectories for processing
Then apply our ANN (homebrew or PyTorch)
%reset -f
Note
In this example, we delete the processed data primarily due to GitHub file size limitations and to demonstrate a clean, reproducible workflow.
In real-world research or applications, you typically do not delete large datasets once downloaded and processed. Instead, you would:
Archive them to a reliable location
Use versioning and metadata to track provenance
Avoid redundant downloads to conserve bandwidth and storage
This cleanup is used here for pedagogical clarity and control, especially in constrained teaching environments.
Data Cleanup Block#
Warning
The code block below will permanently delete all downloaded and generated data, including:
Extracted .mat files and working directories
Converted .png image files
CSV files containing image labels
Only run this cell if:
You want to start fresh
You have already backed up your work (if needed)
You're confident all required artifacts can be re-downloaded and regenerated
This is a reasonable practice to demonstrate reproducibility and manage disk space — but treat it with care!
import shutil
import os
# Define directories to delete
dirs_to_remove = [
"extracted_dataset", # Contains mmc1 and .mat files
"images", # Contains all converted PNGs
"labels" # CSV files mapping filenames to labels
]
for target_dir in dirs_to_remove:
if os.path.exists(target_dir):
print(f"Deleting: {target_dir}")
shutil.rmtree(target_dir)
else:
print(f"Directory not found (already deleted?): {target_dir}")
print("Cleanup complete.")
Directory not found (already deleted?): extracted_dataset
Directory not found (already deleted?): images
Directory not found (already deleted?): labels
Cleanup complete.
import os
import zipfile
import requests
from scipy.io import loadmat
import numpy as np
import matplotlib.pyplot as plt
url = "https://ars.els-cdn.com/content/image/1-s2.0-S002074032100429X-mmc1.zip"
# Step 1: Download the ZIP archive
def download_file(url, output_path):
if not os.path.exists(output_path):
print(f"Downloading {url}...")
response = requests.get(url)
response.raise_for_status()
with open(output_path, "wb") as f:
f.write(response.content)
print(f"Saved to {output_path}")
else:
print(f"File already exists: {output_path}")
# Workflow paths
url = "https://ars.els-cdn.com/content/image/1-s2.0-S002074032100429X-mmc1.zip"
zip_file = "dataset.zip"
extract_dir = "extracted_dataset"
png_output_dir = "images"
# Execute workflow
download_file(url, zip_file)
Downloading https://ars.els-cdn.com/content/image/1-s2.0-S002074032100429X-mmc1.zip...
Saved to dataset.zip
# Step 2: Extract ZIP archive
def extract_zip(zip_path, extract_to):
print(f"Extracting {zip_path}...")
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
zip_ref.extractall(extract_to)
print(f"Extracted to {extract_to}")
extract_zip(zip_file, extract_dir)
Extracting dataset.zip...
Extracted to extracted_dataset
def convert_mat_to_pngs(mat_dir, output_dir):
os.makedirs(output_dir, exist_ok=True)
for filename in os.listdir(mat_dir):
if filename.endswith(".mat"):
full_path = os.path.join(mat_dir, filename)
print(f"Processing {filename}...")
mat_data = loadmat(full_path)
# Try to guess the structure
for key in mat_data:
if not key.startswith("__"):
images = mat_data[key]
# Check dimensions
if images.ndim == 3:
for i in range(images.shape[2]):
img = images[:, :, i]
img = np.squeeze(img)
output_filename = f"{os.path.splitext(filename)[0]}_{i:03d}.png"
plt.imsave(os.path.join(output_dir, output_filename), img, cmap='gray')
elif images.ndim == 4:
for i in range(images.shape[3]):
img = images[:, :, :, i]
output_filename = f"{os.path.splitext(filename)[0]}_{i:03d}.png"
plt.imsave(os.path.join(output_dir, output_filename), img)
else:
print(f"Skipping unexpected shape: {images.shape}")
break # process only first candidate
print("Done.")
convert_mat_to_pngs(os.path.join(extract_dir, "mmc1"), png_output_dir)
Processing NT_NN.mat...
Skipping unexpected shape: (1, 1)
Processing UT_NN.mat...
Skipping unexpected shape: (1, 1)
Processing NT_TestSet_Features.mat...
Skipping unexpected shape: (8, 1407)
Processing ASB_NN.mat...
Skipping unexpected shape: (1, 1)
Processing ASB_TestSet_Features.mat...
Skipping unexpected shape: (21, 3741)
Processing ASB_TestSet_Imgs.mat...
Processing NT_TestSet_Imgs.mat...
Processing UT_TestSet_Imgs.mat...
Processing UT_TestSet_Features.mat...
Skipping unexpected shape: (6, 881)
Done.
This block moves files into subdirectories
import os
import shutil
# Base source directory
source_dir = "./images"
# --- ASB ---
asb_target_dir = os.path.join(source_dir, "ASB")
os.makedirs(asb_target_dir, exist_ok=True)
for filename in os.listdir(source_dir):
if filename.startswith("ASB_Test"):
src_path = os.path.join(source_dir, filename)
dst_path = os.path.join(asb_target_dir, filename)
if os.path.exists(src_path): # only move if it still exists
shutil.move(src_path, dst_path)
# --- NT ---
nt_target_dir = os.path.join(source_dir, "NT")
os.makedirs(nt_target_dir, exist_ok=True)
for filename in os.listdir(source_dir):
if filename.startswith("NT_Test"):
src_path = os.path.join(source_dir, filename)
dst_path = os.path.join(nt_target_dir, filename)
if os.path.exists(src_path):
shutil.move(src_path, dst_path)
# --- UT ---
ut_target_dir = os.path.join(source_dir, "UT")
os.makedirs(ut_target_dir, exist_ok=True)
for filename in os.listdir(source_dir):
if filename.startswith("UT_Test"):
src_path = os.path.join(source_dir, filename)
dst_path = os.path.join(ut_target_dir, filename)
if os.path.exists(src_path):
shutil.move(src_path, dst_path)
import os
import pandas as pd
from scipy.io import loadmat
# --- ASB ---
prefix = "ASB"
mat_path = f"extracted_dataset/mmc1/{prefix}_TestSet_Features.mat"
output_csv = f"labels/{prefix}_labels.csv"
mat_data = loadmat(mat_path)
labels = mat_data['YTest'].squeeze()
filenames = [f"{prefix}_Image_{i:03d}.png" for i in range(len(labels))]
df = pd.DataFrame({'filename': filenames, 'label': labels.astype(int)})
os.makedirs("labels", exist_ok=True)
df.to_csv(output_csv, index=False)
print(f"Saved {len(df)} labels to {output_csv}")
# --- NT ---
prefix = "NT"
mat_path = f"extracted_dataset/mmc1/{prefix}_TestSet_Features.mat"
output_csv = f"labels/{prefix}_labels.csv"
mat_data = loadmat(mat_path)
labels = mat_data['YTest'].squeeze()
filenames = [f"{prefix}_Image_{i:03d}.png" for i in range(len(labels))]
df = pd.DataFrame({'filename': filenames, 'label': labels.astype(int)})
os.makedirs("labels", exist_ok=True)
df.to_csv(output_csv, index=False)
print(f"Saved {len(df)} labels to {output_csv}")
# --- UT ---
prefix = "UT"
mat_path = f"extracted_dataset/mmc1/{prefix}_TestSet_Features.mat"
output_csv = f"labels/{prefix}_labels.csv"
mat_data = loadmat(mat_path)
labels = mat_data['YTest'].squeeze()
filenames = [f"{prefix}_Image_{i:03d}.png" for i in range(len(labels))]
df = pd.DataFrame({'filename': filenames, 'label': labels.astype(int)})
os.makedirs("labels", exist_ok=True)
df.to_csv(output_csv, index=False)
print(f"Saved {len(df)} labels to {output_csv}")
Saved 3741 labels to labels/ASB_labels.csv
Saved 1407 labels to labels/NT_labels.csv
Saved 881 labels to labels/UT_labels.csv
shutil.move("./labels/ASB_labels.csv", "./images/ASB/")
shutil.move("./labels/NT_labels.csv", "./images/NT/")
shutil.move("./labels/UT_labels.csv", "./images/UT/");
The homebrew ANN#
import imageio.v3 as imageio # newer imageio uses imageio.v3
import matplotlib.pyplot as plt
import numpy as np
# Read as float grayscale image
img_array = imageio.imread(
"/home/sensei/ce-5319-webroot/MLBE4CE/chapters/14-neuralnetworks/images/UT/UT_TestSet_Imgs_000.png",
mode='F'
)
# Invert colors and flatten
img_data = 255.0 - img_array.reshape(128 * 128)
# Plot
plt.imshow(np.asarray(img_data).reshape((128, 128)), cmap='Greys')
plt.show()
plt.close('all')

import numpy # useful numerical routines
import scipy.special # special functions library
import scipy.misc # image processing code
#import imageio # deprecated as typical
import imageio.v2 as imageio
import matplotlib.pyplot # import plotting routines
The file pathnames are unique to my computer and are shown here so the notebook renders and typesets correctly.
# now we have to flatten each image, put into a csv file, and add the truth table
# myann expects
# truth, image ....
#howmanyimages = 881
import csv
howmanyimages = 24 # a small subset for demonstration
testimage = numpy.array([i for i in range(howmanyimages)])
split = 0.2 # fraction to hold out for testing
numwritten = 0
# training file
outputfile1 = "ut-881-train.csv" #local to this directory
outfile1 = open(outputfile1,'w') # open the file in the write mode
writer1 = csv.writer(outfile1) # create the csv writer
# testing file
outputfile2 = "ut-881-test.csv" #local to this directory
outfile2 = open(outputfile2,'w') # open the file in the write mode
writer2 = csv.writer(outfile2) # create the csv writer
# process truth table (absolute pathname)
groundtruth = open("/home/sensei/ce-5319-webroot/MLBE4CE/chapters/14-neuralnetworks/images/UT/UT_labels.csv","r") #open the file in the reader mode
reader = csv.reader(groundtruth)
truthtable=[] # empty list to store class
for row in reader:
truthtable.append(row[1])
for irow in range(len(truthtable)-1):
truthtable[irow]=truthtable[irow+1] # shift all entries by 1
#print(truthtable[0:4])
#import imageio.v3 as imageio # use imageio.v3 for mode='F'
#import numpy as np
#import csv
# Assume truthtable, split, howmanyimages, writer1, writer2, outfile1, outfile2 already defined
numwritten = 0
np.random.seed(11)
for i in range(howmanyimages):
# build zero-padded image filename: 000, 001, ...
image_name = f"/home/sensei/ce-5319-webroot/MLBE4CE/chapters/14-neuralnetworks/images/UT/UT_TestSet_Imgs_{i:03}.png"
# read and flatten image
img_array = imageio.imread(image_name, mode='F')
img_data = 255.0 - img_array.flatten() # ensure it's 1D, matches reshape(16384)
# add label to the front
newimage = np.insert(img_data, 0, float(truthtable[i]))
# randomly assign to training or test set
if np.random.uniform() <= split:
writer2.writerow(newimage)
else:
writer1.writerow(newimage)
numwritten += 1
outfile1.close()
outfile2.close()
print("Images segregated and processed:", numwritten)
Images segregated and processed: 24
class neuralNetwork: # Class Definitions
# initialize the neural network
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in input, hidden, and output layer
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# learning rate
self.lr = learningrate
# initalize weight matrices
#
# link weight matrices, wih (input to hidden) and
# who (hidden to output)
# weights inside the arrays are w_i_j where link is from node i
# to node j in next layer
#
# w11 w21
# w12 w22 etc.
self.wih = (numpy.random.rand(self.hnodes, self.inodes) - 0.5)
self.who = (numpy.random.rand(self.onodes, self.hnodes) - 0.5)
# activation function
self.activation_function = lambda x:scipy.special.expit(x)
pass
# train the neural network
def train(self, inputs_list, targets_list):
# convert input list into 2D array
inputs = numpy.array(inputs_list, ndmin=2).T
# convert target list into 2D array
targets = numpy.array(targets_list, ndmin=2).T
# calculate signals into hidden layer
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate signals from hidden layer
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into output layer
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate signals from output layer
final_outputs = self.activation_function(final_inputs)
# calculate output errors (target - model)
output_errors = targets - final_outputs
# calculate hidden layer errors (split by weigths recombined in hidden layer)
hidden_errors = numpy.dot(self.who.T, output_errors)
# update the weights for the links from hidden to output layer
self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)), numpy.transpose(hidden_outputs))
# update the weights for the links from input to hidden layer
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), numpy.transpose(inputs))
pass
# query the neural network
def query(self, inputs_list):
# convert input list into 2D array
inputs = numpy.array(inputs_list, ndmin=2).T
# calculate signals into hidden layer
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate signals from hidden layer
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into output layer
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate signals from output layer
final_outputs = self.activation_function(final_inputs)
return final_outputs
pass
print("neuralNetwork Class Loads OK")
neuralNetwork Class Loads OK
# Test case 1 p130 MYONN
# number of input, hidden, and output nodes
input_nodes = 16384 # 28X28 Pixel Image
hidden_nodes = 1638 # Should be smaller than input count (or kind of useless)
output_nodes = 2 # Classifications
learning_rate = 0.1 # set learning rate
n = neuralNetwork(input_nodes,hidden_nodes,output_nodes,learning_rate) # create an instance
print("Instance n Created")
Instance n Created
# load a training file
# replace code here with a URL get
## training_data_file = open("mnist_train_100.csv",'r') #connect the file#
training_data_file = open("ut-881-train.csv",'r') #connect the file#
training_data_list = training_data_file.readlines() #read entire contents of file into object: data_list#
training_data_file.close() #disconnect the file#
# print(len(training_data_list)) ## activate for debugging otherwise leave disabled
# train the neural network
howManyTrainingTimes = 0
howManyEpisodes = 1
for times in range(howManyEpisodes): # added outer loop for repeat training same data set
howManyTrainingRecords = 0
for record in training_data_list:
# split the values on the commas
all_values = record.split(',') # split datalist on commas - all records. Is thing going to work? #
inputs = (numpy.asarray(all_values[1:], dtype=float) / 255.0 * 0.99) + 0.01
# inputs = (numpy.asarray(all_values[1:])/255.0 * 0.99) + 0.01
# inputs = (numpy.asfarray(all_values[1:])/255.0 * 0.99) + 0.01
# print(inputs) ## activate for debugging otherwise leave disabled
# create target output values -- all 0.01 except for the label of 0.99
targets = numpy.zeros(output_nodes) + 0.01
# all_values[0] is the target for this record
# print(int(numpy.asfarray(all_values[0])))
#targets[int(numpy.asarray(all_values[0]))] = 0.99
targets[int(float(all_values[0]))] = 0.99
# print(targets)
# targets = numpy.asfarray(all_values[0])
n.train(inputs, targets)
howManyTrainingRecords += 1
pass
howManyTrainingTimes += 1
learning_rate *= 0.9
pass
print ("training records processed = ",howManyTrainingRecords)
print ("training episodes = ",howManyTrainingTimes)
# load a production file
test_data_file = open("ut-881-test.csv",'r') #connect the file#
#test_data_file = open("mnist_test.csv",'r') #connect the file#
test_data_list = test_data_file.readlines() #read entire contents of file into object: data_list#
test_data_file.close() #disconnect the file#
training records processed = 16
training episodes = 1
# test the neural network
scorecard = [] # empty array for keeping score
# run through the records in test_data_list
howManyTestRecords = 0
for record in test_data_list:
# split the values on the commas
all_values = record.split(',') # split datalist on commas - all records #
# correct_label = int(all_values[0]) # correct answer is first element of all_values
# correct_label = int(numpy.asarray(all_values[0])) # correct answer is first element of all_values
correct_label = int(float(all_values[0])) # converts '1.0' → 1.0 → 1
# scale and shift the inputs
inputs = (numpy.asarray(all_values[1:], dtype=float)/255.0 * 0.99) + 0.01
# query the neural network
outputs = n.query(inputs)
predict_label = numpy.argmax(outputs)
print("predict =",predict_label,correct_label,"= correct") # activate for small test sets only!
if (predict_label == correct_label):
scorecard.append(1)
else:
scorecard.append(0)
pass
howManyTestRecords += 1
pass
print ("production records processed =", howManyTestRecords)
## print scorecard # activate for small test sets only!
# calculate performance score, fraction of correct answers
scorecard_array = numpy.asarray(scorecard,dtype=int)
print ("performance = ",scorecard_array.sum()/scorecard_array.size)
predict = 1 1 = correct
predict = 1 1 = correct
predict = 1 1 = correct
predict = 1 1 = correct
predict = 1 1 = correct
predict = 1 1 = correct
predict = 1 1 = correct
predict = 1 1 = correct
production records processed = 8
performance = 1.0
# lets try one of my own pictures
# first read and render
#img_array = scipy.misc.imread("cat128.png", flatten = True) Fuckers deprecated this utility!
img_array = imageio.imread("/home/sensei/ce-5319-webroot/MLBE4CE/chapters/14-neuralnetworks/cat128.png", mode='F')
img_data = 255.0 - img_array.reshape(16384)
img_data = ((img_data/255.0)*0.99) + 0.01
matplotlib.pyplot.imshow(numpy.asarray(img_data,dtype=float).reshape((128,128)),cmap = 'Greys') # construct a graphic object #
matplotlib.pyplot.show() # show the graphic object to a window #
matplotlib.pyplot.close('all')
mynumber = n.query(img_data)
mylabel = numpy.argmax(mynumber)
m0=img_data.mean() # gather some statistics
v0=img_data.var()
if mylabel == 0:
msg = "No Cracks Detected"
elif mylabel == 1:
msg = "Cracks Detected"
print ("Cat Image ", msg)
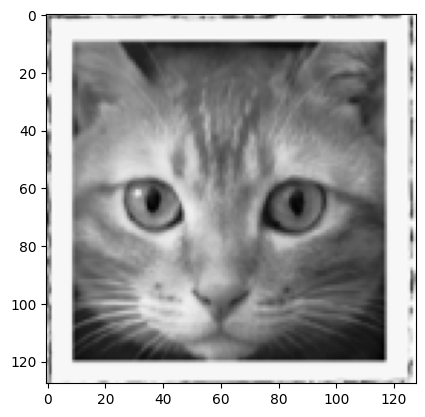
Cat Image Cracks Detected
# lets try one of my own pictures
# first read and render
#img_array = scipy.misc.imread("cat128.png", flatten = True) Fuckers deprecated this utility!
img_array = imageio.imread("/home/sensei/ce-5319-webroot/MLBE4CE/chapters/14-neuralnetworks/waterfall128.png", mode='F')
img_data = 255.0 - img_array.reshape(16384)
img_data = ((img_data/255.0)*0.99) + 0.01
matplotlib.pyplot.imshow(numpy.asarray(img_data,dtype=float).reshape((128,128)),cmap = 'Greys') # construct a graphic object #
matplotlib.pyplot.show() # show the graphic object to a window #
matplotlib.pyplot.close('all')
mynumber = n.query(img_data)
mylabel = numpy.argmax(mynumber)
m0=img_data.mean() # gather some statistics
v0=img_data.var()
if mylabel == 0:
msg = "No Cracks Detected"
elif mylabel == 1:
msg = "Cracks Detected"
print ("Waterfall Image ", msg)

Waterfall Image Cracks Detected
# lets try one of my own pictures
# first read and render
#img_array = scipy.misc.imread("cat128.png", flatten = True) Fuckers deprecated this utility!
img_array = imageio.imread("/home/sensei/ce-5319-webroot/MLBE4CE/chapters/14-neuralnetworks/concrete-cracks.png", mode='F')
img_data = 255.0 - img_array.reshape(16384)
img_data = ((img_data/255.0)*0.99) + 0.01
matplotlib.pyplot.imshow(numpy.asarray(img_data,dtype=float).reshape((128,128)),cmap = 'Greys') # construct a graphic object #
matplotlib.pyplot.show() # show the graphic object to a window #
matplotlib.pyplot.close('all')
mynumber = n.query(img_data)
mylabel = numpy.argmax(mynumber)
m0=img_data.mean() # gather some statistics
v0=img_data.var()
if mylabel == 0:
msg = "No Cracks Detected"
elif mylabel == 1:
msg = "Cracks Detected"
print ("Cracked Concrete ", msg)

Cracked Concrete Cracks Detected