Download (right-click, save target as ...) this page as a jupyterlab notebook Lab20
Laboratory 20: Regression Goodness of Fit
LAST NAME, FIRST NAME
R00000000
ENGR 1330 Laboratory 20 - In Lab
In [1]:
# Preamble script block to identify host, user, and kernel
import sys
! hostname
! whoami
print(sys.executable)
print(sys.version)
print(sys.version_info)
Review of Lesson 20¶
Below is a review, with cool graphics of Lesson 20 content
So far on linear regression ...

- What is linear regression?
a basic predictive analytics technique that uses historical data to predict an output variable. - Why do we need linear regression?
To explore the relationship between predictor and output variables and predict the output variable based on known values of predictors.
- How does linear regression work?
To estimate Y using linear regression, we assume the equation: 𝑌𝑒=β𝑋+α
Our goal is to find statistically significant values of the parameters α and β that minimise the difference between Y and Yₑ. If we are able to determine the optimum values of these two parameters, then we will have the line of best fit that we can use to predict the values of Y, given the value of X. - How to estimate the coefficients? We used a method called "Ordinary Least Squares (OLS)". But that is not the only way. Let's put a pin on that!

Remember when we discussed Probability Density Function (PDF) for the normal distribution? - Probably not!
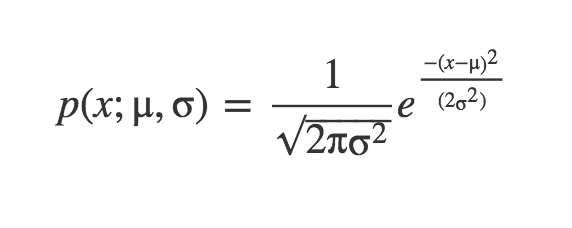
This equation is telling us the probability our sample x from our random variable X, when the true parameters of the distribution are μ and σ.
Example1 :Let’s say our sample is 3, what is the probability it comes from a distribution of μ = 3 and σ = 1? What if it came from a distribution with μ = 7 and σ = 2? Which one is more probable?
In [2]:
import numpy as np
import pandas as pd
import statistics
import scipy.stats
from matplotlib import pyplot as plt
In [2]:
scipy.stats.norm.pdf(3, 3, 1)
Out[2]:
In [3]:
scipy.stats.norm.pdf(3, 7, 2)
Out[3]:
So it is much more likely it came from the first distribution. The PDF equation has shown us how likely those values are to appear in a distribution with certain parameters. Keep that in mind for later. But what if we had a bunch of points we wanted to estimate?¶
Let’s assume we get a bunch of samples fromX which we know to come from some normal distribution, and all are mutually independent from each other. If this is the case, the total probability of observing all of the data is the product of obtaining each data point individually.¶
This should kinda remind you of our class on probability, where we talked about the probability of multiple events happening back to back (e.g., the royal flush set).¶
Example2 : What is the probability of 2 and 6 being drawn from a distribution with μ = 4 and σ = 1
In [4]:
scipy.stats.norm.pdf(2, 4, 1) * scipy.stats.norm.pdf(6, 4, 1)
Out[4]:
Maximum Likelihood Estimation (MLE) is used to specify a distribution of unknown parameters, then using your data to pull out the actual parameter values.To go back to the pin!, let's look at our linear model:¶
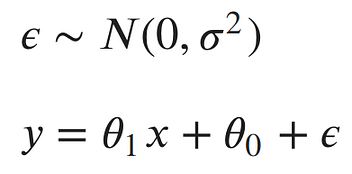
The noise parameter (error) is basically why the points (samples) do not fall exactly on the line. The error for each point would be the distance from the point to our line. We’d like to explicitly include those errors in our model. One method of doing this, is to assume the errors are distributed from a Gaussian distribution with a mean of 0 and some unknown variance σ². The Gaussian seems like a good choice, because our errors look like they’re symmetric about were the line would be, and that small errors are more likely than large errors.
This model has three parameters: the slope and intercept of our line and the variance of the noise distribution. Our main goal is to find the best parameters for the slope and intercept of our line.¶
let’s rewrite our model from above as a single conditional distribution given x:¶

This is equivalent to pushing our x through the equation of the line and then adding noise from the 0 mean Gaussian. Now, we can write the conditional distribution of y given x in terms of this Gaussian. This is just the equation of a Gaussian distribution’s probability density function, with our linear equation in place of the mean:¶
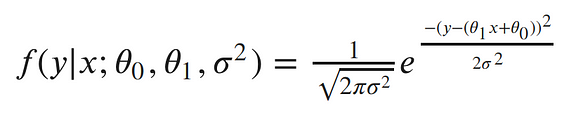
The semicolon in the conditional distribution acts just like a comma, but it’s a useful notation for separating our observed data from the parameters.
Each point is independent and identically distributed (iid), so we can write the likelihood function with respect to all of our observed points as the product of each individual probability density. Since σ² is the same for each data point, we can factor out the term of the Gaussian which doesn’t include x or y from the product:¶
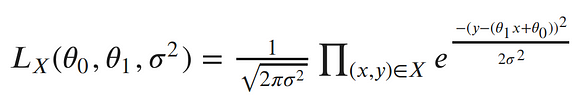
The next step in MLE, is to find the parameters which maximize this function. To make our equation simpler, let’s take the log of our likelihood. Recall, that maximizing the log-likelihood is the same as maximizing the likelihood since the log is monotonic. The natural log cancels out with the exponential, turns products into sums of logs, and division into subtraction of logs; so our log-likelihood looks much simpler:¶
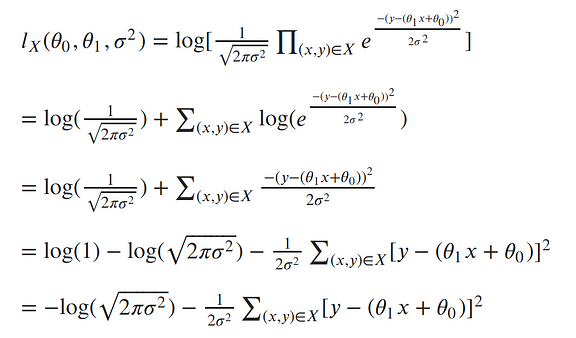
To clean things up a bit more, let’s write the output of our line as a single value:¶
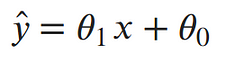
Now our log-likelihood can be written as::¶
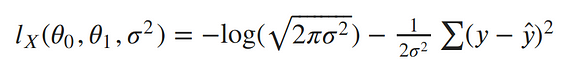
To remove the negative signs, let’s recall that maximizing a number is the same thing as minimizing the negative of the number. So instead of maximizing the likelihood, let’s minimize the negative log-likelihood:¶
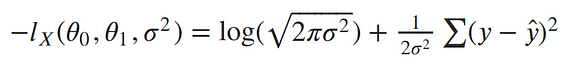
Our ultimate goal is to find the parameters of our line. To minimize the negative log-likelihood with respect to the linear parameters (the θs), we can imagine that our variance term is a fixed constant. Removing any constant’s which don’t include our θs won’t alter the solution. Therefore, we can throw out any constant terms and elegantly write what we’re trying to minimize as:¶
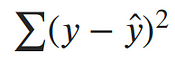
The maximum likelihood estimate for our linear model is the line which minimizes the sum of squared errors!¶

Now, let's solve for parameters. We’ve concluded that the maximum likelihood estimates for our slope and intercept can be found by minimizing the sum of squared errors. Let’s expand out our minimization objective and use i as our index over our n data points:¶
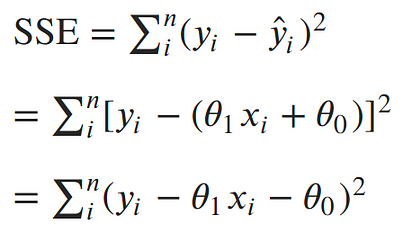
The square in the SSE formula makes it quadratic with a single minimum. The minimum can be found by taking the derivative with respect to each of the parameters, setting it equal to 0, and solving for the parameters in turn.
Taking the partial derivative with respect to the intercept, Setting the derivative equal to 0 and solving for the intercept gives us:¶
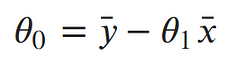
Taking the partial derivative with respect to the slope, Setting the derivative equal to 0 and solving for the slope gives us:¶
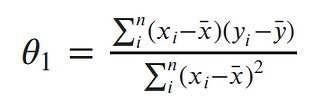
And now it's time to put it all together:¶
In [5]:
def find_line(xs, ys):
"""Calculates the slope and intercept"""
# number of points
n = len(xs)
# calculate means
x_bar = sum(xs)/n
y_bar = sum(ys)/n
# calculate slope
num = 0
denom = 0
for i in range(n):
num += (xs[i]-x_bar)*(ys[i]-y_bar)
denom += (xs[i]-x_bar)**2
slope = num/denom
# calculate intercept
intercept = y_bar - slope*x_bar
return slope, intercept
Example: Let's have a look at the familiar problem from Exam II which was also an Example in the previous lab!
We had a table of recorded times and speeds from some experimental observations. Use MLE to find the intercept and the slope:¶
| Elapsed Time (s) | Speed (m/s) |
|---|---|
| 0 | 0 |
| 1.0 | 3 |
| 2.0 | 7 |
| 3.0 | 12 |
| 4.0 | 20 |
| 5.0 | 30 |
| 6.0 | 45.6 |
| 7.0 | 60.3 |
| 8.0 | 77.7 |
| 9.0 | 97.3 |
| 10.0 | 121.1 |
In [6]:
time = [0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]
speed = [0, 3, 7, 12, 20, 30, 45.6, 60.3, 77.7, 97.3, 121.2]
find_line(time, speed) #Is this similar to our past results?!
Out[6]:
In [7]:
# Predict values
X = np.array(time)
alpha = -16.78636363636364
beta = 11.977272727272727
ypred = alpha + beta * X
# Plot regression against actual data
plt.figure(figsize=(12, 6))
plt.plot(X, speed, 'o') # scatter plot showing actual data
plt.plot(X, ypred, 'r', linewidth=2) # regression line
plt.xlabel('Time (s)')
plt.ylabel('Speed (m/s)')
plt.title('model vs observed')
plt.show()

Goodness-of-Fit
So far, we have assessed the quality of fits visually. We can make numerical assessments as well via Goodness-of-Fit (GOF) measures. Let's discuss three of the most common metrics for evaluating predictions on regression machine learning problems:
Mean Absolute Error (MAE):
The Mean Absolute Error (or MAE) is the average of the absolute differences between predictions and actual values. It gives an idea of how wrong the predictions were. The measure gives an idea of the magnitude of the error, but no idea of the direction (e.g. over or under predicting). Here is the formula:

It is thus an arithmetic average of the absolute errors |ei|=|yi-xi|, where yi is the prediction and xi the true value. This is known as a scale-dependent accuracy measure and therefore cannot be used to make comparisons between series using different scales.In [8]:
# calculate manually
d = speed - ypred
mae_m = np.mean(abs(d))
print("Results by manual calculation:")
print("MAE:",mae_m)
import sklearn.metrics as metrics
mae = metrics.mean_absolute_error(speed, ypred)
print(mae)
Mean Squared Error (MSE) and Root Mean Squared Error (RMSE):
The Mean Squared Error (or MSE) is much like the mean absolute error in that it provides a gross idea of the magnitude of error. It measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. The MSE is a measure of the quality of an estimator—it is always non-negative, and values closer to zero are better. An MSE of zero, meaning that the estimator predicts observations of the parameter with perfect accuracy, is ideal (but typically not possible).Taking the square root of the mean squared error converts the units back to the original units of the output variable and can be meaningful for description and presentation. This is called the Root Mean Squared Error (or RMSE). RMSE is the most widely used metric for regression tasksHere is the formula:

In [9]:
mse_m = np.mean(d**2)
rmse_m = np.sqrt(mse_m)
print("MSE:", mse_m)
print("RMSE:", rmse_m)
mse = metrics.mean_squared_error(speed, ypred)
rmse = np.sqrt(mse) # or mse**(0.5)
print(mse)
print(rmse)
R^2 Metric:
The R^2 (or R Squared) metric provides an indication of the goodness of fit of a set of predictions to the actual values. In statistical literature, this measure is called the coefficient of determination. This is a value between 0 and 1 for no-fit and perfect fit respectively. It provides a measure of how well observed outcomes are replicated by the model, based on the proportion of total variation of outcomes explained by the model..Here is the formula:



In [10]:
r2_m = 1-(sum(d**2)/sum((speed-np.mean(speed))**2))
print("R-Squared:", r2_m)
r2 = metrics.r2_score(speed, ypred)
print(r2)
In [ ]:
Exercise: Advertising and Sells!
Re-using the previous lab and the 'advertising.csv' file, answer the following questions:¶
- Use MLE method and fit a linear regression model with TV advertising spending as predictor for the number of sales for the product.
- Use MLE method and fit a linear regression model with Radio advertising spending as predictor for the number of sales for the product.
- Use MLE method and fit a linear regression model with Newspaper advertising spending as predictor for the number of sales for the product.
- Use MAE, RMSE, and R2 as GOF metrics, and decide which predictor provides a better fit?
In [ ]:
import requests # Module to process http/https requests
remote_url="http://54.243.252.9/engr-1330-webroot/4-Databases/Advertising.csv" # set the url
rget = requests.get(remote_url, allow_redirects=True) # get the remote resource, follow imbedded links
open('Advertising.csv','wb').write(rget.content); # extract from the remote the contents, assign to a local file same name
In [11]:
# Import and display first rows of the advertising dataset
In [1]:
# Use MLE method and fit a linear regression model with TV advertising spending as predictor for the number of sales for the product.
In [2]:
# Use MLE method and fit a linear regression model with Radio advertising spending as predictor for the number of sales for the product.
In [3]:
# Use MLE method and fit a linear regression model with Newspaper advertising spending as predictor for the number of sales for the product.
In [4]:
#Use MAE, RMSE, and R2 as GOF metrics, and decide which predictor provides a better fit?
References¶
This notebook was inspired by several blogposts including:
- "Introduction to Linear Regression in Python" by Lorraine Li available at* https://towardsdatascience.com/introduction-to-linear-regression-in-python-c12a072bedf0
- "In Depth: Linear Regression" available at* https://jakevdp.github.io/PythonDataScienceHandbook/05.06-linear-regression.html
- "A friendly introduction to linear regression (using Python)" available at* https://www.dataschool.io/linear-regression-in-python/
- "What is Maximum Likelihood Estimation — Examples in Python" by Robert R.F. DeFilippi available at* https://medium.com/@rrfd/what-is-maximum-likelihood-estimation-examples-in-python-791153818030
- "Linear Regression" by William Fleshman available at* https://towardsdatascience.com/linear-regression-91eeae7d6a2e
- "Regression Accuracy Check in Python (MAE, MSE, RMSE, R-Squared)" available at* https://www.datatechnotes.com/2019/10/accuracy-check-in-python-mae-mse-rmse-r.html
Here are some great reads on these topics:
- "Linear Regression in Python" by Sadrach Pierre available at* https://towardsdatascience.com/linear-regression-in-python-a1d8c13f3242
- "Introduction to Linear Regression in Python" available at* https://cmdlinetips.com/2019/09/introduction-to-linear-regression-in-python/
- "Linear Regression in Python" by Mirko Stojiljković available at* https://realpython.com/linear-regression-in-python/
- "A Gentle Introduction to Linear Regression With Maximum Likelihood Estimation" by Jason Brownlee available at* https://machinelearningmastery.com/linear-regression-with-maximum-likelihood-estimation/
- "Metrics To Evaluate Machine Learning Algorithms in Python" by Jason Brownlee available at* https://machinelearningmastery.com/metrics-evaluate-machine-learning-algorithms-python/
- "A Gentle Introduction to Maximum Likelihood Estimation" by Jonathan Balaban available at* https://towardsdatascience.com/a-gentle-introduction-to-maximum-likelihood-estimation-9fbff27ea12f
- "Regression: An Explanation of Regression Metrics And What Can Go Wrong" by Divyanshu Mishra available at* https://towardsdatascience.com/regression-an-explanation-of-regression-metrics-and-what-can-go-wrong-a39a9793d914
- "Tutorial: Understanding Regression Error Metrics in Python" available at* https://www.dataquest.io/blog/understanding-regression-error-metrics/
Here are some great videos on these topics:
- "StatQuest: Fitting a line to data, aka least squares, aka linear regression." by StatQuest with Josh Starmer available at* https://www.youtube.com/watch?v=PaFPbb66DxQ&list=PLblh5JKOoLUIzaEkCLIUxQFjPIlapw8nU
- "Statistics 101: Linear Regression, The Very Basics" by Brandon Foltz available at* https://www.youtube.com/watch?v=ZkjP5RJLQF4
- "How to Build a Linear Regression Model in Python | Part 1" and 2,3,4! by Sigma Coding available at* https://www.youtube.com/watch?v=MRm5sBfdBBQ
- "StatQuest: Maximum Likelihood, clearly explained!!!" by StatQuest with Josh Starmer available at* https://www.youtube.com/watch?v=XepXtl9YKwc
- "Maximum Likelihood for Regression Coefficients (part 1 of 3)" and part 2 and 3 by Professor Knudson available at* https://www.youtube.com/watch?v=avs4V7wBRw0
- "StatQuest: R-squared explained" by StatQuest with Josh Starmer available at* https://www.youtube.com/watch?v=2AQKmw14mHM
In [ ]: