Download this page as a jupyter notebook at Lesson 16
# Script block to identify host, user, and kernel
import sys
! hostname; ! whoami; ! pwd;
print(sys.executable)
%%html
<!--Script block to left align Markdown Tables-->
<style>
table {margin-left: 0 !important;}
</style>
Objectives¶
- To apply fundamental concepts involved in probability estimation modeling and descriptive statistics;
- Concept of a hypothesis
- Hypothesis components
- Null hypothesis and alternative hypothesis
- Normal distribution model
- One-tail, two-tail tests
- Attained significance
- Decision Error
- Type-1, Type-2
Computational Thinking Concepts¶
The CT concepts include:
- Abstraction => Represent data behavior with a function
- Pattern Recognition => Patterns in data models to make decision
In statistics, when we wish to start asking questions about the data and interpret the results, we use statistical methods that provide a confidence or likelihood about the answers. In general, this class of methods is called statistical hypothesis testing, or significance tests. The material for today's lecture is inspired by and gathered from several resources including:
- Hypothesis testing in Machine learning using Python by Yogesh Agrawal available at https://towardsdatascience.com/hypothesis-testing-in-machine-learning-using-python-a0dc89e169ce
- Demystifying hypothesis testing with simple Python examples by Tirthajyoti Sarkar available at https://towardsdatascience.com/demystifying-hypothesis-testing-with-simple-python-examples-4997ad3c5294
- A Gentle Introduction to Statistical Hypothesis Testing by Jason Brownlee available at https://machinelearningmastery.com/statistical-hypothesis-tests/
Fundamental Concepts¶
What is hypothesis testing ?
Hypothesis testing is a statistical method that is used in making statistical decisions (about population) using experimental data (samples). Hypothesis Testing is basically an assumption that we make about the population parameter.
Example : You state "on average, students in the class are taller than 5 ft and 4 inches" or "an average boy is taller than an average girl" or "a specific treatment is effective in treating COVID-19 patients".
We need some mathematical way support that whatever we are stating is true. We validate these hypotheses, basing our conclusion on random samples and empirical distributions.
Why do we use it ?
Hypothesis testing is an essential procedure in experimentation. A hypothesis test evaluates two mutually exclusive statements about a population to determine which statement is supported by the sample data. When we say that a finding is statistically significant, it’s thanks to a hypothesis test.
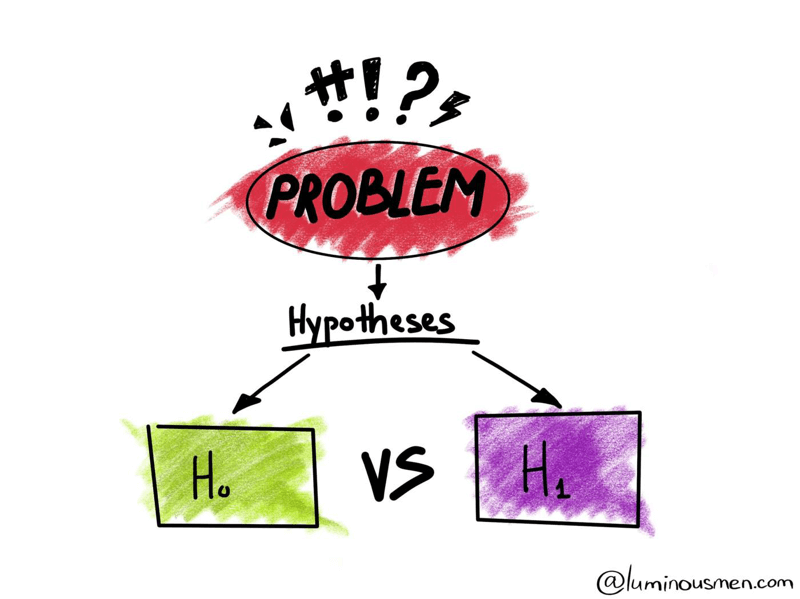
What are important elements of hypothesis testing ?
Null hypothesis :
The assumption of a statistical test is called the null hypothesis, or hypothesis 0 (H0 for short). It is often called the default assumption, or the assumption that nothing has changed. In inferential statistics, the null hypothesis is a general statement or default position that there is no relationship between two measured phenomena, or no association among groups. In other words it is a basic assumption or made based on domain or problem knowledge.
Example : a company' production is = 50 unit/per day.
Alternative hypothesis :
A violation of the test’s assumption is often called the first hypothesis, hypothesis 1 or H1 for short. H1 is really a short hand for “some other hypothesis,” as all we know is that the evidence suggests that the H0 can be rejected. The alternative hypothesis is the hypothesis used in hypothesis testing that is contrary to the null hypothesis. It is usually taken to be that the observations are the result of a real effect (with some amount of chance variation superposed).
Example : a company's production is !=50 unit/per day.
What is the basis of a hypothesis test?
The basis of a hypothesis test is often normalisation and standard normalisation.
All our hypothesis revolve around these 2 terms.
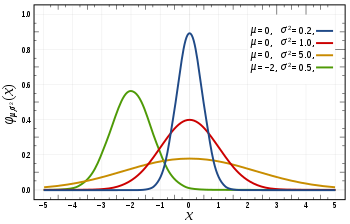
in the 1st image, you can see there are different normal curves. Those normal curves have different means and variances.
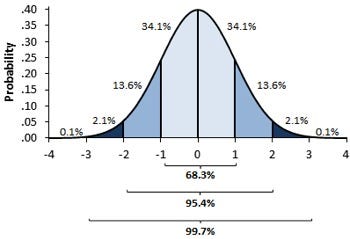
In the 2nd image if you notice the graph is properly distributed with a mean =0 and variance =1. Concept of z-score comes in picture when we use standardized normal data.
Normal Distribution:¶
A variable is said to be normally distributed or have a normal distribution if its distribution has the shape of a normal curve — a special bell-shaped curve. The graph of a normal distribution is called the normal curve, for which the mean, median, and mode are equal. (The 1st Image)
Standardised Normal Distribution:¶
A standard normal distribution is a normal distribution with mean 0 and standard deviation 1 (The 2nd Image)
import math # lesson 13 functions
def normdensity(x,mu,sigma):
weight = 1.0 /(sigma * math.sqrt(2.0*math.pi))
argument = ((x - mu)**2)/(2.0*sigma**2)
normdensity = weight*math.exp(-1.0*argument)
return normdensity
def normdist(x,mu,sigma):
argument = (x - mu)/(math.sqrt(2.0)*sigma)
normdist = (1.0 + math.erf(argument))/2.0
return normdist
# create some observations
import numpy
mu = -2.0
sigma = math.sqrt(0.5)
observations = sigma * numpy.random.randn(100) + mu
observations = numpy.sort(observations)
# print(observations)
pdf = [0 for i in range(observations.size)]
for i in range(observations.size):
pdf[i]=normdensity(observations[i],mu,sigma)
# pdf[i]=normdist(observations[i],mu,sigma)
modeldom = numpy.linspace(mu-4*sigma,mu+4*sigma,200)
modelran = [0 for i in range(modeldom.size)]
for i in range(modeldom.size):
modelran[i]=normdensity(modeldom[i],mu,sigma)
# modelran[i]=normdist(modeldom[i],mu,sigma)
import make2plot # http://54.243.252.9/engr-1330-webroot/1-Lessons/Lesson16/make2plot.py
make2plot.make2plot(observations,pdf,modeldom,modelran,"x","pdf","Normal Distribution") # notice module_name.function_name(arguments) syntax

Z score:
It is a method of expressing data in relation to the group mean. To obtain the Z-score of a particular data, we calculate its deviation from the mean and then divide it by the SD.

The Z score is one way of standardizing a score so that it can be referred to a standard normal distribution curve.

Read more on Z-Score @
- Z-Score: Definition, Formula and Calculation* available at https://www.statisticshowto.com/probability-and-statistics/z-score/
- Z-Score: Definition, Calculation and Interpretation* by Saul McLeod available at https://www.simplypsychology.org/z-score.html
Tailing of Hypothesis:
Depending on the research question hypothesis can be of 2 types. In the Nondirectional (two-tailed) test the Research Question is like: Is there a (statistically) significant difference between scores of Group-A and Group-B in a certain competition? In Directional (one-tailed) test the Research Question is like: Do Group-A score significantly higher than Group-B in a certain competition?

Read more on Tailing @
- One- and two-tailed tests available at https://en.wikipedia.org/wiki/One-_and_two-tailed_tests__
- Z-Score: Definition, Calculation and Interpretation by Saul McLeod available at https://www.simplypsychology.org/z-score.html__
# two samples
mu1 = -1
sigma = math.sqrt(0.5)
sample1 = sigma * numpy.random.randn(1000) + mu1
sample1 = numpy.sort(sample1)
mu2 = 0.0
sigma = math.sqrt(0.5)
sample2 = sigma * numpy.random.randn(1000) + mu2
sample2 = numpy.sort(sample2)
pdf1 = [0 for i in range(sample1.size)]
for i in range(sample1.size):
pdf1[i]=normdensity(sample1[i],mu1,sigma)
# pdf[i]=normdist(observations[i],mu,sigma)
pdf2 = [0 for i in range(sample2.size)]
for i in range(sample2.size):
pdf2[i]=normdensity(sample2[i],mu2,sigma)
# modelran[i]=normdist(modeldom[i],mu,sigma)
make2plot.make2plot(sample1,pdf1,sample2,pdf2,"x","pdf","Normal Distribution") # notice
import matplotlib
a = matplotlib.pyplot.hist(sample1,alpha=0.5)
b = matplotlib.pyplot.hist(sample2,alpha=0.5)


Level of significance:
Refers to the degree of significance in which we accept or reject the null-hypothesis. 100% accuracy is not possible for accepting or rejecting a hypothesis, so we therefore select a level of significance.
This is normally denoted with alpha and generally it is 0.05 or 5% , which means your output should be 95% confident to give similar kind of result in each sample. A smaller alpha value suggests a more robust interpretation of the null hypothesis, such as 1% or 0.1%.
P-value :
The P value, or calculated probability (attained significance), is the probability (p-value) of the collected data, given that the null hypothesis was true. The p-value reflects the strength of evidence against the null hypothesis. Accordingly, we’ll encounter two situations: the evidence is strong enough or not strong enough to reject the null hypothesis.
The p-value is often compared to the pre-chosen alpha value. A result is statistically significant when the p-value is less than alpha. If your P value is less than the chosen significance level then you reject the null hypothesis i.e. accept that your sample gives reasonable evidence to support the alternative hypothesis.
- If p-value > alpha: Do Not Reject the null hypothesis (i.e. not significant result).
- If p-value <= alpha: Reject the null hypothesis (i.e. significant result).

For example, if we were performing a test of whether a data sample was normal and we calculated a p-value of .07, we could state something like:
"The test found that the data sample was normal, failing to reject the null hypothesis at a 5% significance level."
The significance level compliment is determined by subtracting it from 1 to give a confidence level of the hypothesis given the observed sample data.
Therefore, statements such as the following can also be made:
"The test found that the data was normal, failing to reject the null hypothesis at a 95% confidence level."
Example :
you have a coin and you don’t know whether that is fair or tricky so let’s decide null and alternate hypothes is
H0 : a coin is a fair coin.
H1 : a coin is a tricky coin. and alpha = 5% or 0.05
Now let’s toss the coin and calculate p- value ( probability value).
Toss a coin 1st time and result is tail- P-value = 50% (as head and tail have equal probability)
Toss a coin 2nd time and result is tail, now p-value = 50/2 = 25%
and similarly we Toss 6 consecutive times and got result as P-value = 1.5% but we set our significance level as 95% means 5% error rate is allowed and here we see we are beyond that level i.e. our null- hypothesis does not hold good so we need to reject and propose that this coin is not fair.
Read more on p-value @
- P-values Explained By Data Scientist For Data Scientists by Admond Lee available at https://towardsdatascience.com/p-values-explained-by-data-scientist-f40a746cfc8
- What a p-Value Tells You about Statistical Data by Deborah J. Rumsey available at https://www.dummies.com/education/math/statistics/what-a-p-value-tells-you-about-statistical-data/.
- Key to statistical result interpretation: P-value in plain English by Tran Quang Hung available at https://s4be.cochrane.org/blog/2016/03/21/p-value-in-plain-english-2/
Watch more on p-value @
- StatQuest: P Values, clearly explained available at https://www.youtube.com/watch?v=5Z9OIYA8He8
- Understanding the p-value - Statistics Help available at https://www.youtube.com/watch?v=eyknGvncKLw
- What Is A P-Value? - Clearly Explained available at https://www.youtube.com/watch?v=ukcFrzt6cHk
“Reject” vs “Failure to Reject”
The p-value is a probabilistic estimate. This means that when we interpret the result of a statistical test, we do not know what is true or false, only what is likely. Rejecting the null hypothesis means that there is sufficient statistical evidence (from the samples) that the null hypothesis does not look likely (for the population). Otherwise, it means that there is not sufficient statistical evidence to reject the null hypothesis.
We may think about the statistical test in terms of the dichotomy of rejecting and accepting the null hypothesis. The danger is that if we say that we “accept” the null hypothesis, the language suggests that the null hypothesis is true. Instead, it is safer to say that we “fail to reject” the null hypothesis, as in, there is insufficient statistical evidence to reject it.
Errors in Statistical Tests
The interpretation of a statistical hypothesis test is probabilistic. That means that the evidence of the test may suggest an outcome and be mistaken. For example, if alpha was 5%, it suggests that (at most) 1 time in 20 that the null hypothesis would be mistakenly rejected or failed to be rejected (e.g., because of the statistical noise in the data sample).
Having a small p-value (rejecting the null hypothesis) either means that the null hypothesis is false (we got it right) or it is true and some rare and unlikely event has been observed (we made a mistake). If this type of error is made, it is called a false positive. We falsely rejected of the null hypothesis. Alternately, given a large p-value (failing to reject the null hypothesis), it may mean that the null hypothesis is true (we got it right) or that the null hypothesis is false and some unlikely event occurred (we made a mistake). If this type of error is made, it is called a false negative. We falsely believe the null hypothesis or assumption of the statistical test.
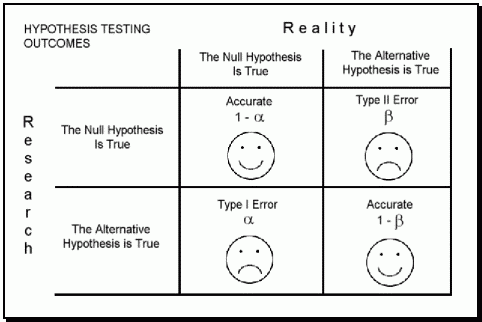
Each of these two types of error has a specific name:
Type I Error: The incorrect rejection of a true null hypothesis or a false positive.
Type II Error: The incorrect failure of rejection of a false null hypothesis or a false negative.

All statistical hypothesis tests have a risk of making either of these types of errors. False findings are more than possible; they are probable!
Ideally, we want to choose a significance level that minimizes the likelihood of one of these errors. E.g. a very small significance level. Although significance levels such as 0.05 and 0.01 are common in many fields of science, harder sciences, such as physics, are more aggressive.
Read more on Type I and Type II Errors @
- Type I and type II errors available at https://en.wikipedia.org/wiki/Type_I_and_type_II_errors#:~:text=In%20statistical%20hypothesis%20testing%2C%20a,false%20negative%22%20finding%20or%20conclusion
- To Err is Human: What are Type I and II Errors? available at https://www.statisticssolutions.com/to-err-is-human-what-are-type-i-and-ii-errors/
- Statistics: What are Type 1 and Type 2 Errors? available at https://www.abtasty.com/blog/type-1-and-type-2-errors/
Some Important Statistical Hypothesis Tests
Variable Distribution Type Tests (Gaussian)
- Shapiro-Wilk Test
- D’Agostino’s K^2 Test
- Anderson-Darling Test
Compare Sample Means (parametric)
- Student’s t-test
- Paired Student’s t-test
- Analysis of Variance Test (ANOVA)
- Repeated Measures ANOVA Test
Compare Sample Means (nonparametric)
- Mann-Whitney U Test
- Wilcoxon Signed-Rank Test
- Kruskal-Wallis H Test
- Friedman Test
Check these excellent links to read more on different Statistical Hypothesis Tests:
- 17 Statistical Hypothesis Tests in Python (Cheat Sheet) by Jason Brownlee available at https://machinelearningmastery.com/statistical-hypothesis-tests-in-python-cheat-sheet/
- Statistical Tests — When to use Which ? by Vibhor Nigam available at https://towardsdatascience.com/statistical-tests-when-to-use-which-704557554740
- Comparing Hypothesis Tests for Continuous, Binary, and Count Data by Jim Frost available at https://statisticsbyjim.com/hypothesis-testing/comparing-hypothesis-tests-data-types/
Normality Tests: Shapiro-Wilk Test
Tests whether a data sample has a Gaussian distribution.
Assumptions:
Observations in each sample are independent and identically distributed (iid).
Interpretation:
- H0: the sample has a Gaussian distribution.
- H1: the sample does not have a Gaussian distribution.
# Example of the Shapiro-Wilk Normality Test
from scipy.stats import shapiro
data = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data
stat, p = shapiro(data)
print('stat=%.3f, p=%.3f' % (stat, p))
alpha = 0.05
if p > alpha :
print('Probably Gaussian')
else:
print('Probably not Gaussian')
Normality Tests: D’Agostino’s K^2 Test
Tests whether a data sample has a Gaussian distribution.
Assumptions:
Observations in each sample are independent and identically distributed (iid).
Interpretation:
- H0: the sample has a Gaussian distribution.
- H1: the sample does not have a Gaussian distribution.
# Example of the D'Agostino's K^2 Normality Test
from scipy.stats import normaltest
data = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = normaltest(data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably Gaussian')
else:
print('Probably not Gaussian')
Read more on Normality Tests @
- A Gentle Introduction to Normality Tests in Python by Jason Brownlee available at https://machinelearningmastery.com/a-gentle-introduction-to-normality-tests-in-python/__
Parametric Statistical Hypothesis Tests: Student’s t-test
Tests whether the means of two independent samples are significantly different.
Assumptions:
- Observations in each sample are independent and identically distributed (iid).
- Observations in each sample are normally distributed.
- Observations in each sample have the same variance.
Interpretation:
- H0: the means of the samples are equal.
- H1: the means of the samples are unequal.
print(sum(data)/10)
print(sum(data2)/10)
# Example of the Student's t-test
from scipy.stats import ttest_ind
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
#data2 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = ttest_ind(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
import numpy
import pandas
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
#data2 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
obj1 = pandas.DataFrame(data1)
obj2 = pandas.DataFrame(data2)
print(obj1.describe())
print(obj2.describe())
myteststatistic =( obj1.mean() - obj2.mean() ) / ((obj1.std() / obj1.count()**(0.5)) + (obj2.std() / obj2.count()**(0.5)))
print(myteststatistic)
Parametric Statistical Hypothesis Tests: Paired Student’s t-test
Tests whether the means of two paired samples are significantly different.
Assumptions:
- Observations in each sample are independent and identically distributed (iid).
- Observations in each sample are normally distributed.
- Observations in each sample have the same variance.
- Observations across each sample are paired.
Interpretation:
- H0: the means of the samples are equal.
- H1: the means of the samples are unequal.
# Example of the Paired Student's t-test
from scipy.stats import ttest_rel
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = ttest_rel(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
Parametric Statistical Hypothesis Tests: Analysis of Variance Test (ANOVA)
Tests whether the means of two or more independent samples are significantly different.
Assumptions:
- Observations in each sample are independent and identically distributed (iid).
- Observations in each sample are normally distributed.
- Observations in each sample have the same variance.
Interpretation:
- H0: the means of the samples are equal.
- H1: one or more of the means of the samples are unequal.
# Example of the Analysis of Variance Test
from scipy.stats import f_oneway
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
data3 = [-0.208, 0.696, 0.928, -1.148, -0.213, 0.229, 0.137, 0.269, -0.870, -1.204]
stat, p = f_oneway(data1, data2, data3)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
Read more on Parametric Statistical Hypothesis Tests @
- How to Calculate Parametric Statistical Hypothesis Tests in Python by Jason Brownlee available at https://machinelearningmastery.com/parametric-statistical-significance-tests-in-python/
Nonparametric Statistical Hypothesis Tests: Mann-Whitney U Test
Tests whether the distributions of two independent samples are equal or not.
Assumptions:
- Observations in each sample are independent and identically distributed (iid).
- Observations in each sample can be ranked.
Interpretation:
- H0: the distributions of both samples are equal.
- H1: the distributions of both samples are not equal.
# Example of the Mann-Whitney U Test
from scipy.stats import mannwhitneyu
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = mannwhitneyu(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
Nonparametric Statistical Hypothesis Tests: Wilcoxon Signed-Rank Test
Tests whether the distributions of two paired samples are equal or not.
Assumptions:
- Observations in each sample are independent and identically distributed (iid).:
- Observations in each sample can be ranked.
- Observations across each sample are paired.
Interpretation:
- H0: the distributions of both samples are equal.
- H1: the distributions of both samples are not equal.
# Example of the Wilcoxon Signed-Rank Test
from scipy.stats import wilcoxon
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = wilcoxon(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
Nonparametric Statistical Hypothesis Tests: Kruskal-Wallis H Test
Tests whether the distributions of two or more independent samples are equal or not.
Assumptions:
- Observations in each sample are independent and identically distributed (iid).
- Observations in each sample can be ranked.
Interpretation:
- H0: the distributions of all samples are equal.
- H1: the distributions of one or more samples are not equal.
# Example of the Kruskal-Wallis H Test
from scipy.stats import kruskal
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = kruskal(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
Read more on Nonparametric Statistical Hypothesis Tests @
- How to Calculate Nonparametric Statistical Hypothesis Tests in Python by Jason Brownlee available at https://machinelearningmastery.com/nonparametric-statistical-significance-tests-in-python/
Example with REAL data: Do construction activities impact stormwater solids metrics?
The webroot for the subsequent examples/exercises is http://54.243.252.9/engr1330content/engr-1330-webroot/9-MyJupyterNotebooks/41A-HypothesisTests/
[Author Note: Copy to .../site/Databases for future on-line textbook]
Background¶
The Clean Water Act (CWA) prohibits storm water discharge from construction sites
that disturb 5 or more acres, unless authorized by a National Pollutant Discharge
Elimination System (NPDES) permit. Permittees must provide a site description,
identify sources of contaminants that will affect storm water, identify appropriate
measures to reduce pollutants in stormwater discharges, and implement these measures.
The appropriate measures are further divided into four classes: erosion and
sediment control, stabilization practices, structural practices, and storm water management.
Collectively the site description and accompanying measures are known as
the facility’s Storm Water Pollution Prevention Plan (SW3P).
The permit contains no specific performance measures for construction activities,
but states that ”EPA anticipates that storm water management will be able to
provide for the removal of at least 80% of the total suspended solids (TSS).” The
rules also note ”TSS can be used as an indicator parameter to characterize the
control of other pollutants, including heavy metals, oxygen demanding pollutants,
and nutrients commonly found in stormwater discharges”; therefore, solids control is
critical to the success of any SW3P.
Although the NPDES permit requires SW3Ps to be in-place, it does not require
any performance measures as to the effectiveness of the controls with respect to
construction activities. The reason for the exclusion was to reduce costs associated
with monitoring storm water discharges, but unfortunately the exclusion also makes
it difficult for a permittee to assess the effectiveness of the controls implemented at
their site. Assessing the effectiveness of controls will aid the permittee concerned
with selecting the most cost effective SW3P.
Problem Statement
The files precon.CSV and durcon.CSV contain observations of cumulative
rainfall, total solids, and total suspended solids collected from a construction
site on Nasa Road 1 in Harris County.
The data in the file precon.CSV was collected before construction began. The data in the file durcon.CSV were collected during the construction activity.
The first column is the date that the observation was made, the second column the total solids (by standard methods), the third column is is the total suspended solids (also by standard methods), and the last column is the cumulative rainfall for that storm.
These data are not time series (there was sufficient time between site visits that you can safely assume each storm was independent. Our task is to analyze these two data sets and decide if construction activities impact stormwater quality in terms of solids measures.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Lets introduce script to automatically get the files from the named resource, in this case a web server!
import requests # Module to process http/https requests
remote_url="http://54.243.252.9/engr1330content/engr-1330-webroot/9-MyJupyterNotebooks/41A-HypothesisTests/precon.csv" # set the url
rget = requests.get(remote_url, allow_redirects=True) # get the remote resource, follow imbedded links
open('precon.csv','wb').write(rget.content) # extract from the remote the contents, assign to a local file same name
remote_url="http://54.243.252.9/engr1330content/engr-1330-webroot/9-MyJupyterNotebooks/41A-HypothesisTests/durcon.csv" # set the url
rget = requests.get(remote_url, allow_redirects=True) # get the remote resource, follow imbedded links
open('durcon.csv','wb').write(rget.content) # extract from the remote the contents, assign to a local file same name
Read and examine the files, see if we can understand their structure
precon = pd.read_csv("precon.csv")
durcon = pd.read_csv("durcon.csv")
precon
durcon
precon.describe()
durcon.describe()
precon.plot.box()

durcon.plot.box()

Here we see that the scales of the two data sets are quite different. Let's see if the two construction phases represent approximately the same rainfall conditions?
precon['RAIN.PRE'].describe()
durcon['RAIN.DUR'].describe()
If we look at the summary statistics, we might conclude there is more rainfall during construction, which could bias our interpretation, a box plot of just rainfall might be useful, as would hypothesis tests.
precon['RAIN.PRE'].plot.box()

durcon['RAIN.DUR'].plot.box()

Hard to tell from the plots, they look a little different, but are they? Lets apply some hypothesis tests
from scipy.stats import mannwhitneyu # import a useful non-parametric test
stat, p = mannwhitneyu(precon['RAIN.PRE'],durcon['RAIN.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
from scipy import stats
results = stats.ttest_ind(precon['RAIN.PRE'], durcon['RAIN.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f ' % (results[0], results[1]))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
From these two tests (the data are NOT paired) we conclude that the two sets of data originate from the same distribution. Thus the question "Do the two construction phases represent approximately the same rainfall conditions?" can be safely answered in the affirmative.
Continuing, lets ask the same about total solids, first plots:
precon['TS.PRE'].plot.box()

durcon['TS.DUR'].plot.box()

Look at the difference in scales, the during construction phase, is about 5 to 10 times greater. But lets apply some tests to formalize our interpretation.
stat, p = mannwhitneyu(precon['TS.PRE'],durcon['TS.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
results = stats.ttest_ind(precon['TS.PRE'], durcon['TS.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f ' % (results[0], results[1]))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
Both these tests indicate that the data derive from distirbutions with different measures of central tendency (means).
Lets now ask the question about normality, we will apply a test called normaltest. This function tests a null hypothesis that a sample comes from a normal distribution. It is based on D’Agostino and Pearson’s test that combines skew and kurtosis to produce an omnibus test of normality. We will likely get a warning because our sample size is pretty small.
stat, p = stats.normaltest(precon['TS.PRE'])
print('statistic=%.3f, p-value at rejection =%.3f' % (stat, p))
if p > 0.05:
print('Probably normal distributed')
else:
print('Probably Not-normal distributed')
stat, p = stats.normaltest(durcon['TS.DUR'])
print('statistic=%.3f, p-value at rejection =%.3f' % (stat, p))
if p > 0.05:
print('Probably normal distributed')
else:
print('Probably Not-normal distributed')
References¶
D’Agostino, R. B. (1971), “An omnibus test of normality for moderate and large sample size”, Biometrika, 58, 341-348
D’Agostino, R. and Pearson, E. S. (1973), “Tests for departure from normality”, Biometrika, 60, 613-622
# script block to identify host, user, and kernel
import sys
! echo 'HID ' $HOSTNAME
! echo 'UID ' $USER
print('path to kernel == ' + sys.executable)
# print(sys.version)
print(sys.version_info)
#! pwd
Functions as Data Models¶
We have already examined functions as data models, and did trial and error fitting to "calibrate" a function to some data, then used that function to predict unobserved responses. However there are ways to have the machine perform the fit on our behalf - here we will examine one such way on a subset of models.
Polynomial data model:¶
Polynomial Model: $y_{model} = \beta_0 + \beta_1 x_{obs} + \beta_2 x_{obs}^2 + ... + \beta_n x_{obs}^n$
One way to "fit" this models to data is to construct a design matrix $X$ comprised of $x_{obs}$ and ones (1). Then construct a linear system related to this design matrix.
The data model as a linear system is:
$$\begin{gather} \mathbf{X} \cdot \mathbf{\beta} = \mathbf{Y} \end{gather}$$For example using the Polynomial Model (order 2 for brevity, but extendable as justified)
\begin{gather} \mathbf{X}= \begin{pmatrix} 1 & x_1 & x_1^2\\ ~\\ 1 & x_2 & x_2^2\\ ~ \\ 1 & x_3 & x_3^2\\ \dots & \dots & \dots \\ 1 & x_n & x_n^2\\ \end{pmatrix} \end{gather}\begin{gather} \mathbf{\beta}= \begin{pmatrix} \beta_0 \\ ~\\ \beta_1 \\ ~ \\ \beta_2 \\ \end{pmatrix} \end{gather}\begin{gather} \mathbf{X}= \begin{pmatrix} y_1 \\ ~\\ y_2 \\ ~ \\ y_3 \\ \dots \\ y_n \\ \end{pmatrix} \end{gather}To find the unknown $\beta$ values the solution of the linear system below provides a "best linear unbiased estimator (BLUE)" fit
$$\begin{gather} [\mathbf{X^T}\mathbf{X}] \cdot \mathbf{\beta} = [\mathbf{X^T}]\mathbf{Y} \end{gather}$$or an alternative expression is
$$\begin{gather} \mathbf{\beta} = [\mathbf{X^T}\mathbf{X}]^{-1}[\mathbf{X^T}]\mathbf{Y} \end{gather}$$Once the values for $\beta$ are obtained then we can apply our plotting tools and use the model to extrapolate and interpolate. The logarithmic, power, and exponential model will involve functions of $x$ which are known, and inverse transformations.
Consider the data collected during the boost-phase of a ballistic missle. The maximum speed of a solid-fueled missle at burn-out (when the boost-phase ends) is about 7km/s. Using this knowledge and the early-time telemetry below; fit a data model using the linear system approach and use the model to estimate boost phase burn-out. Plot the model and data on the same axis to demonstrate the quality of the fit.
| Elapsed Time (s) | Speed (m/s) |
|---|---|
| 0 | 0 |
| 1.0 | 3 |
| 2.0 | 7.4 |
| 3.0 | 16.2 |
| 4.0 | 23.5 |
| 5.0 | 32.2 |
| 6.0 | 42.2 |
| 7.0 | 65.1 |
| 8.0 | 73.5 |
| 9.0 | 99.3 |
| 10.0 | 123.4 |
First lets make two lists
time = [0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0]
speed = [0,3,7.4,16.2,23.5,32.2,42.2, 65.1 ,73.5 ,99.3 ,123.4,]
Then define our model structure, here just a polynomial of degree 2 (a quadratic).
def polynomial(b0,b1,b2,time):
polynomial = b0+b1*time+b2*time**2
return(polynomial)
Now we will use numpy to build the design matrix $X$ comprised of $x_{obs}$ and ones (1), and the various transposes, and such.
import numpy
X = [numpy.ones(len(time)),numpy.array(time),numpy.array(time)**2] # build the design X matrix #
X = numpy.transpose(X) # get into correct shape for linear solver
Y = numpy.array(speed) # build the response Y vector
A = numpy.transpose(X)@X # build the XtX matrix
b = numpy.transpose(X)@Y # build the XtY vector
x = numpy.linalg.solve(A,b) # just solve the linear system
print(x) # look at the answers
Now make a list of model responses to input values
responses = [0 for i in range(len(time))]
for i in range(len(time)):
responses[i] = polynomial(x[0],x[1],x[2],time[i])
print(responses) # look at the responses
Import our plotting script, and plot the data (red) and the data model (blue) on same plot.
import make2plot # http://54.243.252.9/engr-1330-webroot/1-Lessons/Lesson16/make2plot.py
make2plot.make2plot(time,speed,time,responses,"Time","Speed","Kim's da bomb!") # notice module_name.function_name(arguments) syntax

time_to_burnout = float(input('Enter estimated time since begin boost phase '))
print('Estimated Speed (m/sec) :',polynomial(x[0],x[1],x[2],time_to_burnout))
Power-Law Model:¶
A useful model in engineering is a power-law model
$y_{model} = \beta_0 x_{obs}^{\beta_1} $
However it does not look very "linear", but a simple transformation by taking logs yields
$log(y_{model}) = log10(\beta_0)+ \beta_1 log10(x_{obs}) $
which is linear in the unknown coefficients $\beta_0$ and $\beta_1$.
Using the same data we can construct a power-law model, automatically fit it and then plot to find out how well our moeld performs.
#¶
def powerlaw(b0,b1,time):
powerlaw = b0*time**b1
return(powerlaw)
time = [0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0]
speed = [0,3,7.4,16.2,23.5,32.2,42.2, 65.1 ,73.5 ,99.3 ,123.4,]
for i in range(len(time)):
time[i]=time[i]+ 0.00001 # offset so don't log zeroes
speed[i]=speed[i]+ 0.00001
X = [numpy.ones(len(time)),numpy.array(numpy.log10(time))] # build the design X matrix
X = numpy.transpose(X) # get into correct shape for linear solver
Y = numpy.array(numpy.log10(speed)) # build the response Y vector
A = numpy.transpose(X)@X # build the XtX matrix
b = numpy.transpose(X)@Y # build the XtY vector
x = numpy.linalg.solve(A,b) # just solve the linear system
print(x) # look at the answers
responses = [0 for i in range(len(time))]
for i in range(len(time)):
responses[i] = powerlaw(10**x[0],x[1],time[i])
print(responses) # look at the responses
make2plot.make2plot(time,speed,time,responses,"Time","Speed","Power-Law Model") # notice module_name.function_name(arguments) syntax

Exponential Model:¶
Another useful model in engineering is an exponential model
$y_{model} = \beta_0 e^{{\beta_1}x_{obs}} $
However it does not look very "linear", but a simple transformation by taking logs yields
$log(y_{model}) = log(\beta_0)+ \beta_1*(x_{obs}) $
which is linear in the unknown coefficients $\beta_0$ and $\beta_1$. Notice that it is quite similar to a power-law model, but not identical.
Using the same data we can construct an exponential model, automatically fit it and then plot to find out how well our moeld performs.
#¶
def expmodel(b0,b1,time):
import math # somewhat overkill - but import wont hurt anything
expmodel = b0*math.exp(b1*time)
return(expmodel)
time = [0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0]
speed = [0,3,7.4,16.2,23.5,32.2,42.2, 65.1 ,73.5 ,99.3 ,123.4,]
for i in range(len(time)):
time[i]=time[i]+ 0.00001 # offset so don't log zeroes
speed[i]=speed[i]+ 0.00001
X = [numpy.ones(len(time)),numpy.array(time)] # build the design X matrix
X = numpy.transpose(X) # get into correct shape for linear solver
Y = numpy.array(numpy.log(speed)) # build the response Y vector
A = numpy.transpose(X)@X # build the XtX matrix
b = numpy.transpose(X)@Y # build the XtY vector
x = numpy.linalg.solve(A,b) # just solve the linear system
print(x) # look at the answers
responses = [0 for i in range(len(time))]
import math
for i in range(len(time)):
responses[i] = expmodel(math.exp(x[0]),x[1],time[i])
print(responses) # look at the responses
make2plot.make2plot(time,speed,time,responses,"Time","Speed","Exponential Model") # notice module_name.function_name(arguments) syntax

Descriptive Statistics with Python¶
A fundamental part of working with data is describing it. Descriptive statistics help simplify and summarize large amounts of data in a sensible manner. In this lecture, we will discuss descriptive statistics and cover a variety of methods for summarizing, describing, and representing datasets in Python. The contents of this notebook are inspired by various online resources including the following links:
"Descriptive statistics with Python-NumPy" by Rashmi Jain, available @ https://www.hackerearth.com/blog/developers/descriptive-statistics-python-numpy/.
"Python Statistics Fundamentals: How to Describe Your Data" by Mirko Stojiljković , available @ https://realpython.com/python-statistics/.
"A Quick Guide on Descriptive Statistics using Pandas and Seaborn" by Bee Guan Teo, available @ https://towardsdatascience.com/a-quick-guide-on-descriptive-statistics-using-pandas-and-seaborn-2aadc7395f32.
"Tutorial: Basic Statistics in Python — Descriptive Statistics" , available @ https://www.dataquest.io/blog/basic-statistics-with-python-descriptive-statistics/.
We will use the "HighestGrossingMovies.csv" dataset as an illustrative example. Let's have a look at it first.
######### CODE TO AUTOMATICALLY DOWNLOAD THE DATABASE ################
#! pip install requests #install packages into local environment
import requests # import needed modules to interact with the internet
# make the connection to the remote file (actually its implementing "bash curl -O http://fqdn/path ...")
remote_url = 'http://54.243.252.9/engr-1330-webroot/4-Databases/HighestGrossingMovies.csv' # a csv file
response = requests.get(remote_url) # Gets the file contents puts into an object
output = open('HighestGrossingMovies.csv', 'wb') # Prepare a destination, local
output.write(response.content) # write contents of object to named local file
output.close() # close the connection
#Import the necessary external packages
import numpy as np
import pandas as pd
Movies = pd.read_csv("HighestGrossingMovies.csv") #Dataset of the Top10 highest-grossing films as of 2019 (adjusted for inflation)
#5 columns (Movie, Director, Year, Budget, Gross) and 10 rows
Movies
Here is an overall look at some but not all of measures we will be discussing today:
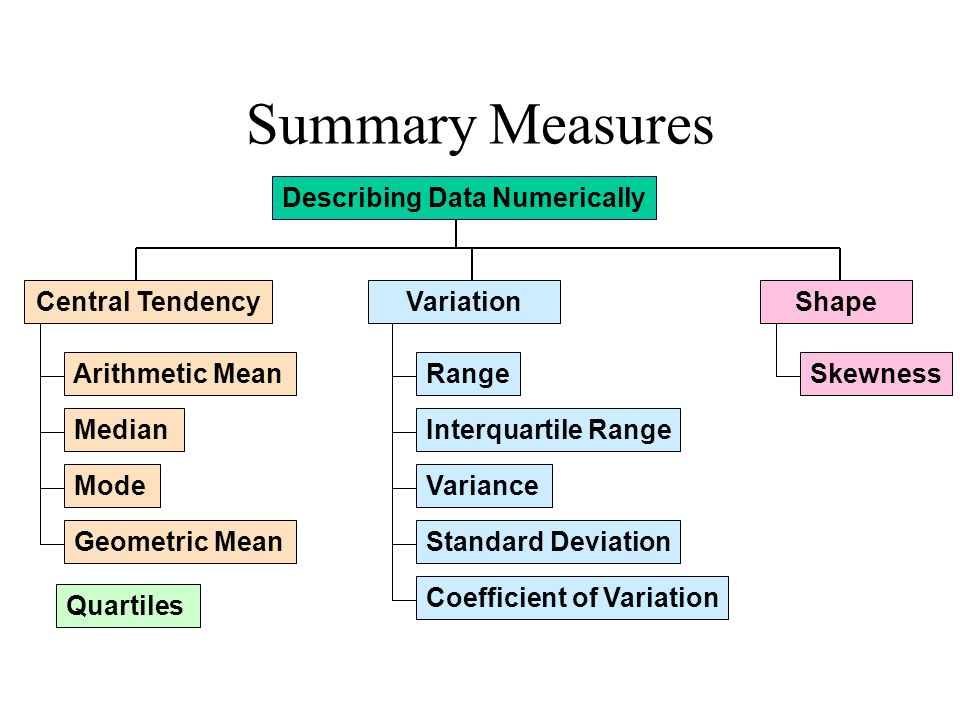
Measures of Central Tendency
Centrality measures give us an estimate of the center of a distribution and a sense of a typical value we would expect to see.
The three major measures of center include the mean, median, and mode.
Mean
The arithmetic mean (average) is the sum of all the values, divided by the number of values. Mean represents the typical value that acts as a yardstick for all observations.

Let's calculate the average budget of the Top10 highest-grossing films.
Budget = Movies['Budget_million$']
Budget
We can use primitive python to calculate the mean of set of numbers:
# Create a list of all the numbers:
budget = [3.9,237,200,11,356,8.2,10.5,13,11,306]
mean1 = sum(budget) / len(budget)
print("The average budget of the Top10 highest-grossing films is ",mean1,"million USD")
We can also utilize a variety of external libraries. (You may find some of them familiar!)
# The usual suspects!
import numpy as np
import pandas as pd
# Also, these two libraries offer useful functions for descriptive statistics
import statistics
import scipy.stats
# Read the column of interest from the Movies dataframe
Budget = Movies['Budget_million$']
# Use the mean function from the Pandas library
mean2 = Budget.mean()
print("The average budget of the Top10 highest-grossing films is ",mean2,"million USD")
# Read the column of interest from the Movies dataframe
Budget = Movies['Budget_million$']
# Use the mean function from the Numpy library
mean3 = np.mean(Budget)
print("The average budget of the Top10 highest-grossing films is ",mean3,"million USD")
# Read the column of interest from the Movies dataframe
Budget = Movies['Budget_million$']
# Use the mean function from the statistics library
mean4 = statistics.mean(Budget)
print("The average budget of the Top10 highest-grossing films is ",mean4,"million USD")
Harmonic Mean
The harmonic mean is the reciprocal of the mean of the reciprocals of all items in the dataset.
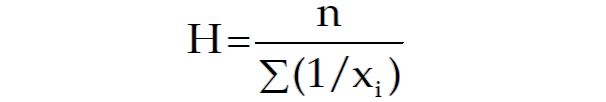
Let's calculate the harmonic mean for the same set of numbers:
# Primitive Python:
budget = [3.9,237,200,11,356,8.2,10.5,13,11,306]
hmean1 = len(budget) / sum(1 / item for item in budget)
hmean1 = round(hmean1,2)
print("The harmonic mean of the budget of the Top10 highest-grossing films is ",hmean1,"million USD")
# via the Statistics library:
Budget = Movies['Budget_million$']
hmean2 = statistics.harmonic_mean(Budget)
hmean2 = round(hmean2,2)
print("The harmonic mean of the budget of the Top10 highest-grossing films is ",hmean2,"million USD")
# via the scipy.stats library:
Budget = Movies['Budget_million$']
hmean3 = scipy.stats.hmean(Budget)
hmean3 = round(hmean3,2)
print("The harmonic mean of the budget of the Top10 highest-grossing films is ",hmean3,"million USD")
Geometric Mean
The geometric mean is the 𝑛-th root of the product of all 𝑛 elements 𝑥ᵢ in a dataset.

Let's calculate the geometric mean for the same set of numbers:
# Primitive Python: -it is getting more lengthy and labour-intensive
budget = [3.9,237,200,11,356,8.2,10.5,13,11,306]
gmean1 = 1
for item in budget:
gmean1 *= item
gmean1 **= 1 / len(budget)
gmean1 = round(gmean1,2)
print("The geometric mean of the budget of the Top10 highest-grossing films is ",gmean1,"million USD")
# via the Statistics library:
Budget = Movies['Budget_million$']
gmean2 = statistics.geometric_mean(Budget)
gmean2 = round(gmean2,2)
print("The geometric mean of the budget of the Top10 highest-grossing films is ",gmean2,"million USD")
# via the scipy.stats library:
Budget = Movies['Budget_million$']
gmean3 = scipy.stats.gmean(Budget)
gmean3 = round(gmean3,2)
print("The geometric mean of the budget of the Top10 highest-grossing films is ",gmean3,"million USD")
Arithmetic or Geometric or Harmonic?- How to be Mean!

- If values have the same units: Use the arithmetic mean.
- If values have differing units: Use the geometric mean.
- Also, commonly used for growth rates, like population growth or interest rates.
- If values are rates: Use the harmonic mean.
Learn More: If you are interested in knowing more about these 3 and their differences, you may find these sources interesting:
"Arithmetic, Geometric, and Harmonic Means for Machine Learning Arithmetic, Geometric, and Harmonic Means for Machine Learning" by Jason Brownlee, available @ https://machinelearningmastery.com/arithmetic-geometric-and-harmonic-means-for-machine-learning/#:~:text=The%20arithmetic%20mean%20is%20appropriate,with%20different%20measures%2C%20called%20rates.
"On Average, You’re Using the Wrong Average: Geometric & Harmonic Means in Data Analysis" by Daniel McNichol, available @ https://towardsdatascience.com/on-average-youre-using-the-wrong-average-geometric-harmonic-means-in-data-analysis-2a703e21ea0
Median
Median is the middle element of a sorted dataset. The value where the upper half of the data lies above it and lower half lies below it. In other words, it is the middle value of a data set. To calculate the median, arrange the data points in the increasing (or decreasing) order and the middle value is the median. If the number of elements 𝑛 of the dataset is odd, then the median is the value at the middle position: 0.5(𝑛 + 1). If 𝑛 is even, then the median is the arithmetic mean of the two values in the middle, that is, the items at the positions 0.5𝑛 and 0.5𝑛 + 1. Let's find the median of the gross of the Top10 highest-grossing films:
Gross = Movies['Gross_million$']
Gross
We can use primitive python to calculate the median of a set of numbers:
# Create a list of all the numbers:
gross = [3706,3257,3081,3043,2798,2549,2489,2356,2233,2202]
n = len(gross)
if n % 2:
median1 = sorted(gross)[round(0.5*(n-1))]
else:
gross_ord, index = sorted(gross), round(0.5 * n)
median1 = 0.5 * (gross_ord[index-1] + gross_ord[index])
print("The median of gross of the Top10 highest-grossing films is ",median1,"million USD")
We can use also use external libraries:
#via the Pandas library:
Gross = Movies['Gross_million$']
median2 = Gross.median()
print("The median of gross of the Top10 highest-grossing films is ",median2,"million USD")
#via the Numpy library:
Gross = Movies['Gross_million$']
median3 = np.median(Gross)
print("The median of gross of the Top10 highest-grossing films is ",median3,"million USD")
#via the Statistics library:
Gross = Movies['Gross_million$']
median4 = statistics.median(Gross)
print("The median of gross of the Top10 highest-grossing films is ",median4,"million USD")
#2 more functions from the same library- For even number of cases:
print("low median :",statistics.median_low(Gross))
print("high median :",statistics.median_high(Gross))
The main difference between the behavior of the mean and median is related to dataset outliers or extremes. The mean is heavily affected by outliers, but the median only depends on outliers either slightly or not at all. You can compare the mean and median as one way to detect outliers and asymmetry in your data. Whether the mean value or the median value is more useful to you depends on the context of your particular problem. The mean is a better choice when there are no extreme values that can affect it. It is a better summary because the information from every observation is included rather than median, which is just the middle value. However, in the presence of outliers, median is considered a better alternative. Check this out:
newgross = [99999,3257,3081,3043,2798,2549,2489,2356,2233,2202] #We have replaced 3706 with 99999- an extremely high number (an outlier)
newmean = np.mean(newgross)
newmedian = np.median(newgross)
print(newmean) #A huge change from the previous value (115.66) - Mean is very sensitive to outliers and extreme values
print(newmedian) #No Change- the median only depends on outliers either slightly or not at all.
To read more about the differences of mean and median, check these out:
"Stuck in the middle – mean vs. median" , available @ https://www.clinfo.eu/mean-median/
"Mean vs Median: When to Use Which Measure?" , available @ https://www.datascienceblog.net/post/basic-statistics/mean_vs_median/
"Mean vs. Median" by AnswerMiner, available @ https://www.answerminer.com/blog/mean-vs-median
Mode
The value that occurs the most number of times in our data set. Closely tied to the concept of frequency, mode provides information on the most recurrent elements in a dataset. When the mode is not unique, we say that the data set is bimodal, while a data set with more than two modes is multimodal. Let's find the mode in the gross of the Top10 highest-grossing films:
# In primitive Python:
# Create a list of all the numbers:
gross = [3706,3257,3081,3043,2798,2549,2489,2356,2233,2202]
mode1 = max((gross.count(item), item) for item in gross)[1]
print(mode1) #Since each item is repeated only once, only the first element is printed- This is a multimodal set.
#via the Pandas library:
Gross = Movies['Gross_million$']
mode2 = Gross.mode()
print(mode2) #Returns all modal values- This is a multimodal set.
#via the Statistics library:
Gross = Movies['Gross_million$']
mode3 = statistics.mode(Gross)
print(mode3) #Return a single value
mode4 = statistics.multimode(Gross)
print(mode4) #Returns a list of all modes
#via the scipy.stats library:
Gross = Movies['Gross_million$']
mode5 = scipy.stats.mode(Gross)
print(mode5) #Returns the object with the modal value and the number of times it occurs- If multimodal: only the smallest value
Mode is not useful when our distribution is flat; i.e., the frequencies of all groups are similar. Mode makes sense when we do not have a numeric-valued data set which is required in case of the mean and the median. For instance:
Director = Movies['Director']
# via statistics:
mode6 = statistics.mode(Director)
print(mode6) #"James Cameron" with two films (x2 repeats) is the mode
# via pandas:
mode7 = Director.mode()
print(mode7) #"James Cameron" with two films (x2 repeats) is the mode
To read more about mode, check these out:
"Mode: A statistical measure of central tendency" , available @ https://corporatefinanceinstitute.com/resources/knowledge/other/mode/
"When to use each measure of Central Tendency" , available @ https://courses.lumenlearning.com/introstats1/chapter/when-to-use-each-measure-of-central-tendency/
"Mean, Median, Mode: What They Are, How to Find Them" , available @ https://www.statisticshowto.com/probability-and-statistics/statistics-definitions/mean-median-mode/
Measures of Dispersion
Measures of dispersion are values that describe how the data varies. It gives us a sense of how much the data tends to diverge from the typical value. Aka measures of variability, they quantify the spread of data points.The major measures of dispersion include range, percentiles, inter-quentile range, variance, standard deviation, skeness and kurtosis.
Range
The range gives a quick sense of the spread of the distribution to those who require only a rough indication of the data. There are some disadvantages of using the range as a measure of spread. One being it does not give any information of the data in between maximum and minimum. Also, the range is very sensitive to extreme values. Let's calculate the range for the budget of the Top10 highest-grossing films:
# Primitive Python:
budget = [3.9,237,200,11,356,8.2,10.5,13,11,306]
range1 = max(budget)-min(budget)
print("The range of the budget of the Top10 highest-grossing films is ",range1,"million USD")
# via the Statistics library:
Budget = Movies['Budget_million$']
range2 = np.ptp(Budget) #ptp stands for Peak To Peak
print("The range of the budget of the Top10 highest-grossing films is ",range2,"million USD")
Percentiles and Quartiles
A measure which indicates the value below which a given percentage of points in a dataset fall. The sample 𝑝 percentile is the element in the dataset such that 𝑝% of the elements in the dataset are less than or equal to that value. Also, (100 − 𝑝)% of the elements are greater than or equal to that value. For example, median represents the 50th percentile. Similarly, we can have 0th percentile representing the minimum and 100th percentile representing the maximum of all data points. Percentile gives the relative position of a particular value within the dataset. It also helps in comparing the data sets which have different means and deviations. Each dataset has three quartiles, which are the percentiles that divide the dataset into four parts:
- The first quartile (Q1) is the sample 25th percentile. It divides roughly 25% of the smallest items from the rest of the dataset.
- The second quartile Q2) is the sample 50th percentile or the median. Approximately 25% of the items lie between the first and second quartiles and another 25% between the second and third quartiles.
- The third quartile (Q3) is the sample 75th percentile. It divides roughly 25% of the largest items from the rest of the dataset.
Budget = Movies['Budget_million$']
#via Numpy:
p10 = np.percentile(Budget, 10) #returns the 10th percentile
print("The 10th percentile of the budget of the Top10 highest-grossing films is ",p10)
p4070 = np.percentile(Budget, [40,70]) #returns the 40th and 70th percentile
print("The 40th and 70th percentile of the budget of the Top10 highest-grossing films are ",p4070)
#via Pandas:
p10n = Budget.quantile(0.10) #returns the 10th percentile - notice the difference from Numpy
print("The 10th percentile of the budget of the Top10 highest-grossing films is ",p10n)
#via Statistics:
Qs = statistics.quantiles(Budget, n=4, method='inclusive') #The parameter n defines the number of resulting equal-probability percentiles:
#n=4 returns the quartiles | n=2 returns the median
print("The quartiles of the budget of the Top10 highest-grossing films is ",Qs)
InterQuartile Range (IQR)
IQR is the difference between the third quartile and the first quartile (Q3-Q1). The interquartile range is a better option than range because it is not affected by outliers. It removes the outliers by just focusing on the distance within the middle 50% of the data.
Budget = Movies['Budget_million$']
#via Numpy:
IQR1 = np.percentile(Budget, 75) -np.percentile(Budget, 25) #returns the IQR = Q3-Q1 = P75-P25
print("The IQR of the budget of the Top10 highest-grossing films is ",IQR1)
#via scipy.stats:
IQR2 = scipy.stats.iqr(Budget) #returns the IQR- Can be used for other percentile differences as well >> iqr(object, rng=(p1, p2))
print("The IQR of the budget of the Top10 highest-grossing films is ",IQR2)
The Five-number Summary
A five-number summary is especially useful in descriptive analyses or during the preliminary investigation of a large data set. A summary consists of five values: the most extreme values in the data set (the maximum and minimum values), the lower and upper quartiles, and the median. Five-number summary can be used to describe any data distribution. Boxplots are extremely useful graphical representation of the 5-number summary that we will discuss later.
Budget = Movies['Budget_million$']
Budget.describe() #Remember this jewel from Pandas? -It directly return the 5-number summary AND MORE!
Boxplots are extremely useful graphical representation of the 5-number summary. It can show the range, interquartile range, median, mode, outliers, and all quartiles.
import matplotlib.pyplot as plt #Required for the plot
gross = [3706,3257,3081,3043,2798,2549,2489,2356,2233,2202,5000] #same data + an outlier: 5000
fig = plt.figure(figsize =(7, 5))
plt.boxplot(gross,medianprops={'linewidth': 1, 'color': 'purple'})
plt.show()

To read more about the 5-number summary, check these out:
"Find a Five-Number Summary in Statistics: Easy Steps" , available @ https://www.statisticshowto.com/how-to-find-a-five-number-summary-in-statistics/
"The Five-Number Summary" , available @ https://www.purplemath.com/modules/boxwhisk2.htm
"What Is the 5 Number Summary?" by Courtney Taylor, available @ https://www.statisticshowto.com/probability-and-statistics/statistics-definitions/mean-median-mode/
Variance
The sample variance quantifies the spread of the data. It shows numerically how far the data points are from the mean. The observations may or may not be meaningful if observations in data sets are highly spread. Let's calculate the variance for budget of the Top10 highest-grossing films.
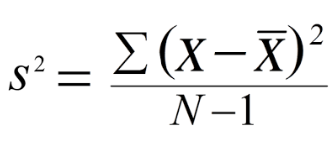
Note that if we are working with the entire population (and not the sample), the denominator should be "n" instead of "n-1".
Note that if we are working with the entire population (and not the sample), the denominator should be "n" instead of "n-1".
# Primitive Python:
budget = [3.9,237,200,11,356,8.2,10.5,13,11,306]
n = len(budget)
mean = sum(budget) / n
var1 = sum((item - mean)**2 for item in budget) / (n - 1)
print("The variance of the budget of the Top10 highest-grossing films is ",var1)
# via the Statistics library:
Budget = Movies['Budget_million$']
var2 = statistics.variance(Budget)
print("The variance of the budget of the Top10 highest-grossing films is ",var2)
Standard Deviation
The sample standard deviation is another measure of data spread. It’s connected to the sample variance, as standard deviation, 𝑠, is the positive square root of the sample variance. The standard deviation is often more convenient than the variance because it has the same unit as the data points.
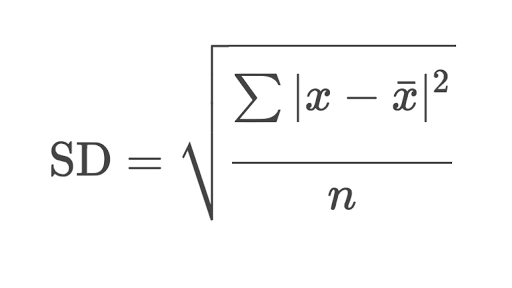
# Primitive Python:
budget = [3.9,237,200,11,356,8.2,10.5,13,11,306]
n = len(budget)
mean = sum(budget) / n
var = sum((item - mean)**2 for item in budget) / (n - 1)
sd1 = var**0.5
print("The standard deviation of the budget of the Top10 highest-grossing films is ",sd1,"million USD")
# via the Statistics library:
Budget = Movies['Budget_million$']
sd2 = statistics.stdev(Budget)
print("The standard deviation of the budget of the Top10 highest-grossing films is ",sd2,"million USD")
Skewness
The sample skewness measures the asymmetry of a data sample. There are several mathematical definitions of skewness. The Fisher-Pearson standardized moment coefficient is calculated by using mean, median and standard deviation of the data.

Usually, negative skewness values indicate that there’s a dominant tail on the left side. Positive skewness values correspond to a longer or fatter tail on the right side. If the skewness is close to 0 (for example, between −0.5 and 0.5), then the dataset is considered quite symmetrical.
# Primitive Python:
budget = [3.9,237,200,11,356,8.2,10.5,13,11,306]
n = len(budget)
mean = sum(budget) / n
var = sum((item - mean)**2 for item in budget) / (n - 1)
std = var**0.5
skew1 = (sum((item - mean)**3 for item in budget)
* n / ((n - 1) * (n - 2) * std**3))
print("The skewness of the budget of the Top10 highest-grossing films is ",skew1)
# via the scipy.stats library:
Budget = Movies['Budget_million$']
skew2 = scipy.stats.skew(Budget, bias=False)
print("The skewness of the budget of the Top10 highest-grossing films is ",skew2)
# via the Pandas library:
Budget = Movies['Budget_million$']
skew3 = Budget.skew()
print("The skewness of the budget of the Top10 highest-grossing films is ",skew3)
Kurtosis
Kurtosis describes the peakedness of the distribution. In other words, Kurtosis identifies whether the tails of a given distribution contain extreme values. While Skewness essentially measures the symmetry of the distribution, kurtosis determines the heaviness of the distribution tails.
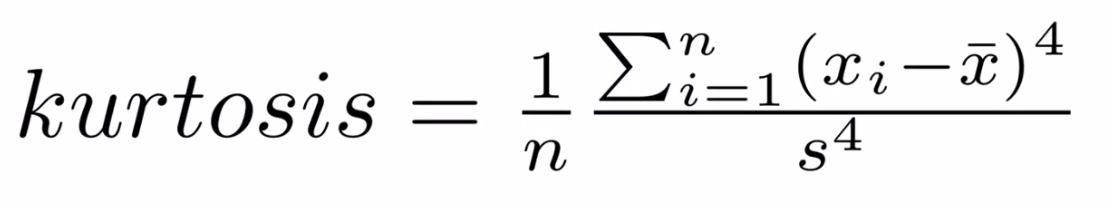
If the distribution is tall and thin it is called a leptokurtic distribution. Values in a leptokurtic distribution are near the mean or at the extremes. A flat distribution where the values are moderately spread out (i.e., unlike leptokurtic) is called platykurtic distribution. A distribution whose shape is in between a leptokurtic distribution and a platykurtic distribution is called a mesokurtic distribution.
# via the scipy.stats library:
Budget = Movies['Budget_million$']
Kurt = scipy.stats.kurtosis(Budget)
print("The kurtosis of the budget of the Top10 highest-grossing films is ",Kurt) #a platykurtic distribution | the tails are heavy
To read more about skewness and kurtosis, check these out:
"Measures of Skewness and Kurtosis" , available @ https://www.itl.nist.gov/div898/handbook/eda/section3/eda35b.htm#:~:text=Skewness%20is%20a%20measure%20of,relative%20to%20a%20normal%20distribution.
"Are the Skewness and Kurtosis Useful Statistics?" , available @ https://www.spcforexcel.com/knowledge/basic-statistics/are-skewness-and-kurtosis-useful-statistics
"Skew and Kurtosis: 2 Important Statistics terms you need to know in Data Science" by Diva Dugar, available @ https://codeburst.io/2-important-statistics-terms-you-need-to-know-in-data-science-skewness-and-kurtosis-388fef94eeaa
"Measures of Shape: Skewness and Kurtosis" by Stan Brown, available @ https://brownmath.com/stat/shape.htm