Example 1 Problem Solving Process¶
Consider a need to compute an arithmetic mean, what would the process look like?
Step 1. Develop script to compute the arithmetic mean of a stream of data of unknown length.
Step 2.
- Inputs: The data stream
- Governing equation: $ \bar x = \frac{1}{N} \sum_{i=1}^{N} x_i $ where $N$ is the number of items in the data stream, and $x_i$ is the value of the i-th element.
- Outputs: The arithmetic mean $\bar x$
Step 3. Work a sample problem by-hand for testing the general solution.
| Data |
|---|
| 23.43 |
| 37.43 |
| 34.91 |
| 28.37 |
| 30.62 |
The arithmetic mean requires us to count how many elements are in the data stream (in this case there are 5) and compute their sum (in this case 154.76), and finally divide the sum by the count and report this result as the arithmetic mean.
$$ \bar x = \frac{1}{5}(23.43+37.43+34.91+28.37+30.62)=\frac{154.76}{5}=30.95 $$Step 4. Develop a general solution (code)
The by-hand exercise helps identify the required steps in an “algorithm” or recipe to compute mean values. First we essentially capture or read the values then count how many there are (either as we go or as a separate step), then sum the values, then divide the values by the count, and finally report the result.
In a flow-chart it would look like:
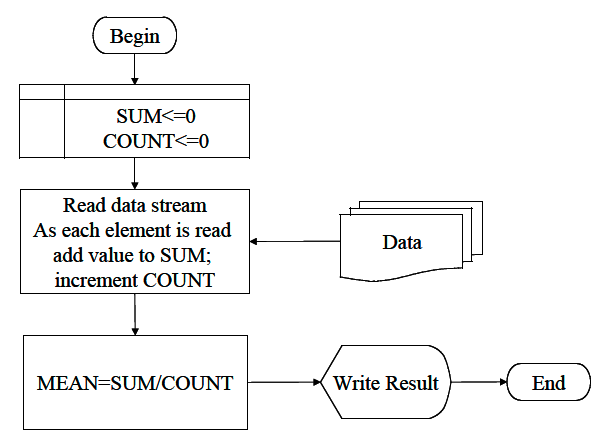
| Flowchart for Artihmetic Mean Algorithm | ||
|---|---|---|
Step 5. This step we would code the algorithm expressed in the figure and test it with the by-hand data and other small datasets until we are convinced it works correctly.
In a simple JupyterLab script